Forward and backward propagation in neural networks
Deduce forward propagation and back propagation algorithms of neural network with single hidden layer, and program (neural network in ‘Sklearn’ can be used).
discuss the impact of 10,30,100,300,1000, different number of hidden nodes on network performance.
Explore the influence of different learning rate and iteration times on network performance.
Change the standardized method of data to explore the impact on training.
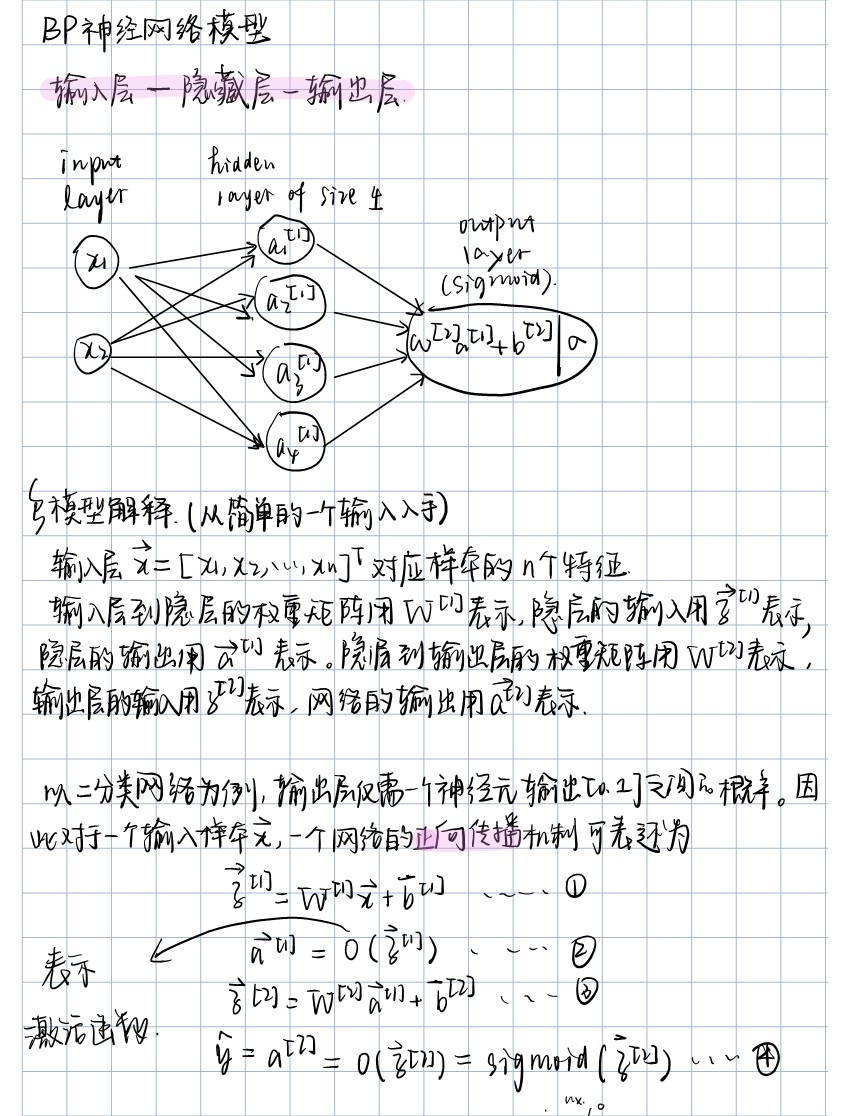
Derivation
Code
Load data
# 1、载入数据 import numpy as np import tensorflow as tf import tensorflow.examples.tutorials.mnist.input_data as input_data
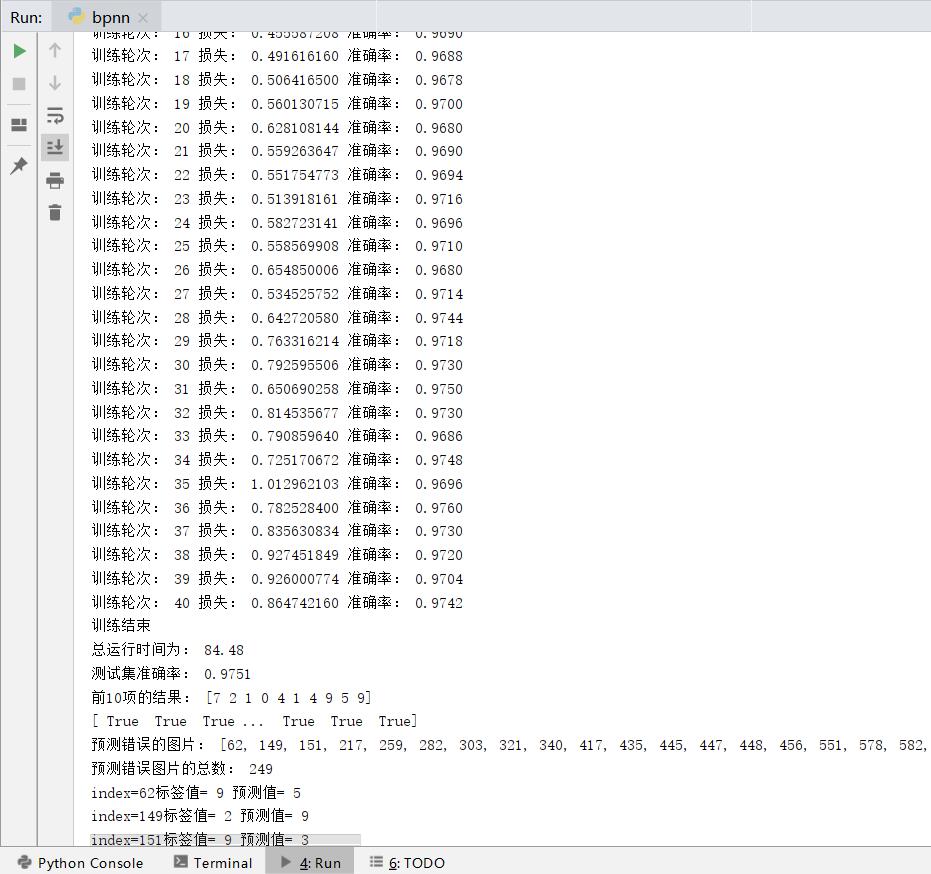
The number of hidden layer nodes: 256 Learning Rate: 0.01 Epochs: 40
Optimization
The number of hidden layer nodes
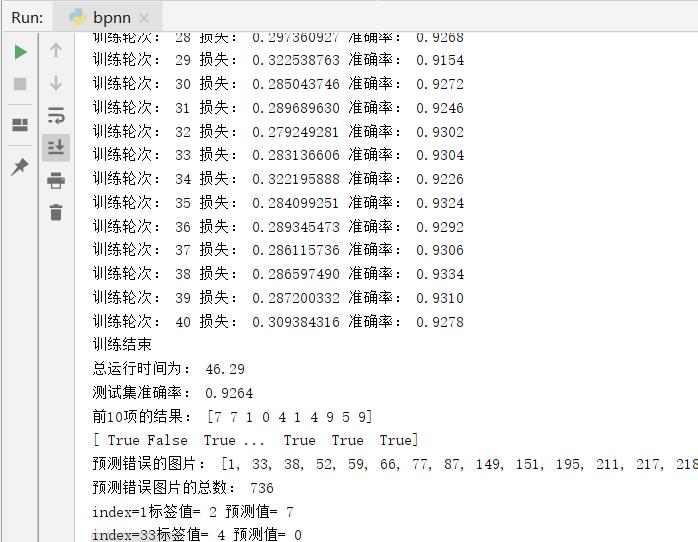
The number of hidden layer nodes: 10
# of hidden layer nodes
Running Time/s
False
Acc.
10
46.29
736
0.9264
30
43.46
528
0.9472
100
59.06
343
0.9657
256
84.48
249
0.9751
300
76.64
269
0.9731
1000
302.27
240
0.976
As can be seen from the table, the accuracy increases with the increase of the number of hidden layer nodes, and the increase rate gradually decreases.
Learning Rate
LR
Running Time/s
False
Acc.
0.005
78.81
231
0.9769
0.01
84.48
249
0.9751
0.02
69.72
446
0.9554
0.1
73.87
2561
0.7439
As can be seen from the table, the accuracy decreases with the increase of the learning rate. When the learning rate is lower than 0.01, the rate of improvement of image classification accuracy is small.
Epochs
Epochs
Running Time/s
False
Acc.
20
37.12
307
0.9693
40
84.48
249
0.9751
100
184.39
239
0.9761
As can be seen from the table, the number of iterations has a great impact on the total running time, and the accuracy increases with the increase of the number of iterations, but the number of nodes in the hidden layer and the learning rate are the decisive factors for the accuracy.
Implement a one-layer network
deflayer_sizes(X, Y): n_x = X.shape[0] # size of input layer n_h = 4# size of hidden layer n_y = Y.shape[0] # size of output layer return (n_x, n_h, n_y)
defcompute_cost(A2, Y, parameters): m = Y.shape[1] # number of example # Compute the cross-entropy cost logprobs = np.multiply(np.log(A2),Y) + np.multiply(np.log(1-A2), 1-Y) cost = -1/m * np.sum(logprobs) cost = np.squeeze(cost) # makes sure cost is the dimension we expect. assert(isinstance(cost, float)) return cost