MCM 2020 | Sentiment Analysis | Find the relationship between review and star ranking
This is my second time for MCM & ICM. I teamed up with two friends. This is how we divide the work: one of my friends collecting information and the other writing the essay. I was responsible for modeling and coding. We finally got Meritorious Winner(Top 5%). I’m so proud of it.
Topic & Dataset
Topic
In the online marketplace it created, Amazon provides customers with an opportunity to rate and review purchases. Individual ratings - called “star ratings” - allow purchasers to express their level of satisfaction with a product using a scale of 1 (low rated, low satisfaction) to 5 (highly rated, high satisfaction). Additionally, customers can submit text-based messages - called “reviews” - that express further opinions and information about the product. Other customers can submit ratings on these reviews as being helpful or not - called a “helpfulness rating” - towards assisting their own product purchasing decision. Companies use these data to gain insights into the markets in which they participate, the timing of that participation, and the potential success of product design feature choices.
Sunshine Company is planning to introduce and sell three new products in the online marketplace: a microwave oven, a baby pacifier, and a hair dryer. They have hired your team as consultants to identify key patterns, relationships, measures, and parameters in past customer-supplied ratings and reviews associated with other competing products to 1) inform their online sales strategy and 2) identify potentially important design features that would enhance product desirability. Sunshine Company has used data to inform sales strategies in the past, but they have not previously used this particular combination and type of data. Of particular interest to Sunshine Companyare time-based patterns in these data, and whether they interact in ways that will help the company craft successful products.
To assist you, Sunshine’s data center has provided you with three data files for this project: hair_dryer.tsv, microwave.tsv, and pacifier.tsv. These data represent customer-supplied ratings and reviews for microwave ovens, baby pacifiers, and hair dryers sold in the Amazon marketplace over the time period(s) indicated in the data. A glossary of data label definitions is provided as well.
Dataset
The three data sets provided contain product user ratings and reviews extracted from the Amazon Customer Reviews Dataset thru Amazon Simple Storage Service (Amazon S3).
hair_dryer.tsvmicrowave.tsvpacifier.tsv
Data Set Definitions: Each row represents data partitioned into the following columns.
- marketplace (string): 2 letter country code of the marketplace where the review was written.
- customer_id (string): Random identifier that can be used to aggregate reviews written by a single author.
- review_id (string): The unique ID of the review.
- product_id (string): The unique Product ID the review pertains to.
- product_parent (string): Random identifier that can be used to aggregate reviews for the same product.
- product_title (string): Title of the product.
- product_category (string): The major consumer category for the product.
- star_rating (int): The 1-5 star rating of the review.
- helpful_votes (int): Number of helpful votes.
- total_votes (int): Number of total votes the review received.
- vine (string): Customers are invited to become Amazon Vine Voices based on the trust that they have earned in the Amazon community for writing accurate and insightful reviews. Amazon provides Amazon Vine members with free copies of products that have been submitted to the program by vendors. Amazon doesn’t influence the opinions of Amazon Vine members, nor do they modify or edit reviews.
- verified_purchase (string): A “Y” indicates Amazon verified that the person writing the review purchased the product at - Amazon and didn’t receive the product at a deep discount.
- review_headline (string): The title of the review.
- review_body (string): The review text.
- review_date (bigint): The date the review was written.
Overview
Through data mining and modeling, we analyze the three types of products sales and provide a marketing strategy for Sunshine Company.
First of all, we preprocess the data. We fully analyze the 15 attributes in microwaves, pacifiers and hair dryers, filter them and syntheze three new attributes: review_text, popularity and reputation. We deal with missing values in the data set and remove those meaningless reviews. Through the Tokenization algorithm, we cut the sentence of the review headline and the review body into single words, which is convenient for us to analyze the emotion of the user and understand the relationship between reviews and star ratings.
Furthermore, we use the TF-IDF(Term FrequencyInverse Document Frequency) algorithm and MLP(Multi-layer Perceptron) to build a model and try to discover the relationship between reviews and star ratings. We use reviews to evaluate the products and use helpful votes to evaluate reviews, through this way we build a multi-dimension evaluation system. The TF-IDF algorithm uses the segmented words to generate a word frequency matrix, which is used as the input of the MLP. And the products’ star ratings are used as the output. We build models for the three types of products respectively, for the reviews of the three types of products have some differences, which may affect the accuracy of the results. The data set is divided into training set and test set. When the model training is completed, the effect of the model is tested with the test set. After the practice, our prediction is very similar to the ground truth. Then we get the relationship between star ratings and reviews. The traditional MLP model has poor interpretability, so we continue to do semantic analysis on this basis, which enhances the interpretability of the whole model.
Eventually , we analyze the time-based popularity changes of the product, and make marketing suggestions to the Sunshine Company from the customer’s perspective. Through analysis, we found that the products’ popularity always reach the highest at the beginning and middle of each year, so the company could make promotional activities at that time to raise their profile. In this way, we found the relationship between period and popularity. From the perspective of customers, we observe that those users who score 5 stars or 1 star often quite emotional when giving reviews. We recommend three types of the most valuable users and select their reviews for the sunshine company. They are AmazonVine Voices Members, users who have purchased multiple similar products and users who have given one-star rate to the product. By analyzing the WordCloud of reviews of those who have given one-star rates, we can know how to improve the products.
Preparation for the modeling
For the data mining problems that have large quantity and types of data, there are often a large number of default values, which may affect the efficiency and accuracy of the model. Therefore, the processing of these default values is of vital importance. In addition, in this data set, there is a large amount of text information in attributes such as prouct_title, and review_headline. Thus our team choose the tokenization algorithm to classify and organize the text information.
Default Value Preprocessing
Through our analysis, in all the given data sets, only the review_headline and review_body attributes are default. The Amazon website stipulates that when a review is submitted, its star_rating, review_headline and review_body must be filled in, otherwise the review cannot be submitted. so the lack of data is not caused by user behavior, but created during the collection, transmission or storage of these reviews. Therefore, the “default” here does not contain customers opinions towards the product.
In this case our team deal with the default records in this way.
- When only one of the review_headline or review_body is default, we will keep this data. Because it still contains a large amount of information;
- When both of the review_headline and review_body are default, We will abandon this data. Because review is an essential part of our following analysis, in this case when both of them are default, this data is of little significance for data
mining.
Tokenization
The main goal of Tokenization is to normalize our texts, that is, to process a paragraph of text into short, non-redundant text information. Our tokenization process
includes the following steps:
a. Lowercase the values.
Because the text_market, product_title and other text attributes have a kind of phenomenon that some values with the same meaning have different capitalization. For example, the marketplace attribute contains ’US’ and ’us’, which is not convenient for our subsequent classification of products. Therefore, we convert all text to lower
case.
b. Break the sentences into token
c. Remove punctuation and stop words
In computing, stop words are words which are filtered out before or after processing of natural language data (text).
We give an example in Figure 1.

Figure 1: An example about Tokenization in Microwave Product Data Set
Data Selection and Synthesis
In these 15 attributes that come from the provided data sets, some of them are not valuable. So we need to select the relatively more essential attributes. For the marketplace attribute, all evaluations in the dataset are from the US, so there is no reason to do data mining on this attribute, similarly in product_cetegory. Review_id is only used to distinguish different reviews, so we delete their corresponding data as well.
Before introducing product_id and product_parent, we need to learn more about parent-child relationships.
Each parent product may contain multiple child products, and each child parents may be different in sizes, colors, or prices. Each parent product corresponds to a product_parent, and each child product corresponds to a product_id. In the following data analysis, we mainly analyze the parent product and inspect these three types of products from a macro level. Take the microwave as an example, the parent-child product relationship as shown below.
In Figure 2 , we can find the four child products have different product_ids and they may have different sizes, colors or prices. However, they have the same product_parent. Please notice that we don’t know the specific information about these four child products.Their colors and sizes in Figure 2 are just for example.
We choose these following basic attributes in Table 1 to create the Customer Profile. Additionally, some synthetic variables are used in our model. These variables are described in Table 2.
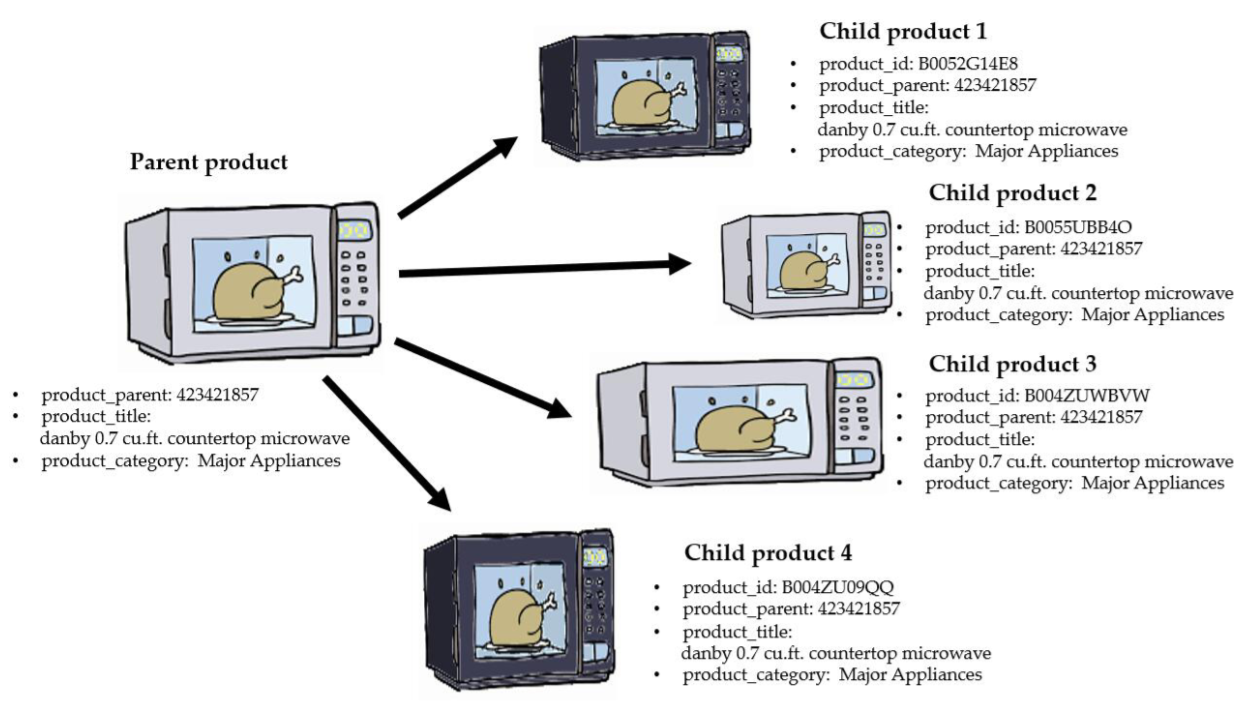
Figure 2: The Parent-Child Relationship in Microwave Products

Competing Products Analysis
First we visualize the data sets to show the profiles of the three products. The number of reviews and parent products are shown in Table 3.
Here is the products profile of microwave, the other two products are attached to the appendix. Figure 3 shows the star ratings and the number of reviews of every parent products. The horizontal axis reprensents the product titles.
For Microwaves, we select the product that has the most reviews - “Danby 0.7 cu.ft. Countertop Microwave” to analyze its reviews. Before we create the wordcloud of review_text, we take stemming operations. Stemming is the process of reducing inflected (or sometimes derived) words to their word stem, base or root formgenerally a written word form.
In Figure 5, High frequency words has bigger font size. In Figure 6, horizontal axis represents the review headline.
In addition to the above analysis from the perspective of the product itself, we also try to delete the click farmers or construct Customer Profile from the user’s perspective. Through the Customer Profile, we can have a better understanding toward the interests of the target users, and thus we could provide better product services.
We observe that a large number of users have bought more than one product. So we check out several reviews and found that many of them are click farmers, and their invalid reviews cannot be checked out through the helpful_votes, so eventually we manually deleted these reviews. For others who have really bought many products, we think their opinions are as valuable as those of Amazon Vine Voices Members. Therefore, we filtered out 53 reviews from 9 users who have purchased more than 5 products and sent these comments to Sunshine Company for their reference. These 9 user comments are detailed in the appendix.

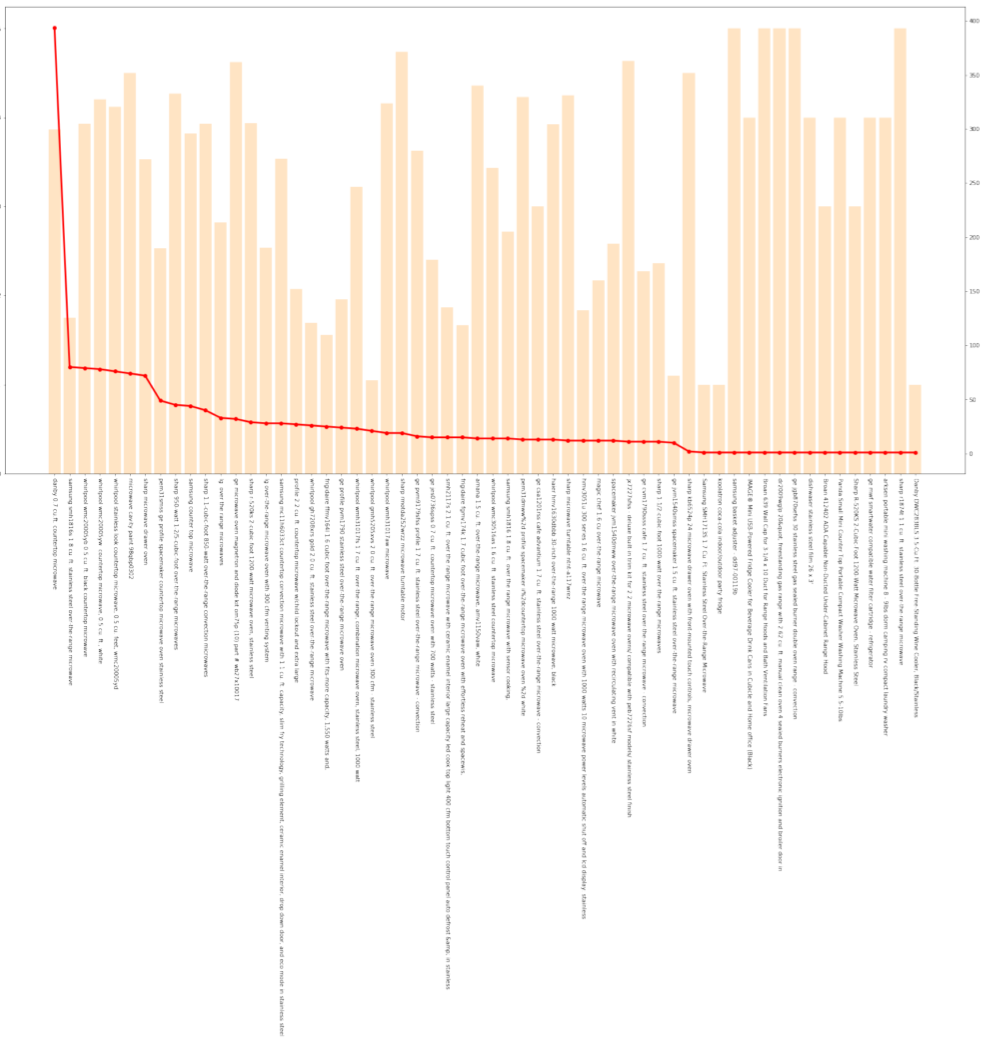
Figure 3: The Star Ratings and the Number of Reviews of Microwave
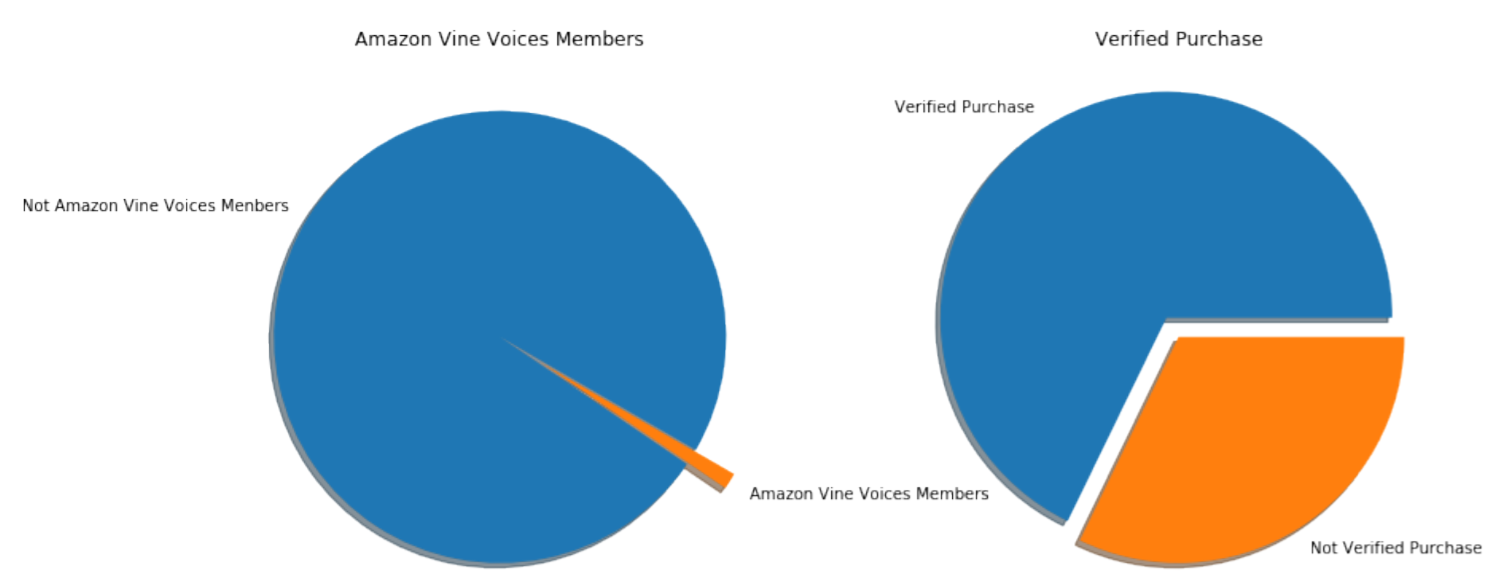
Figure 4: The proportion of People Who Were in Amazon Vine and People Who Had Bought the Product
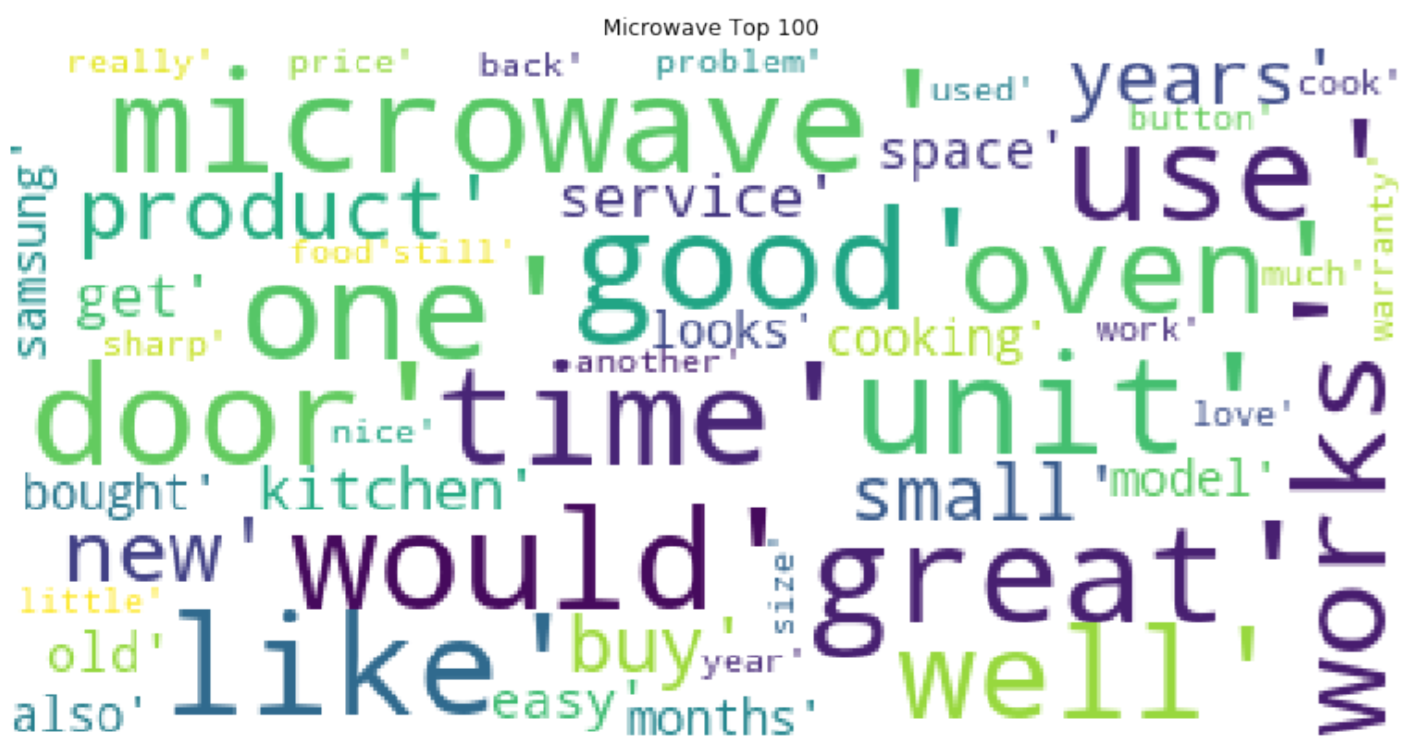
Figure 5: The Wordcloud of Microwave
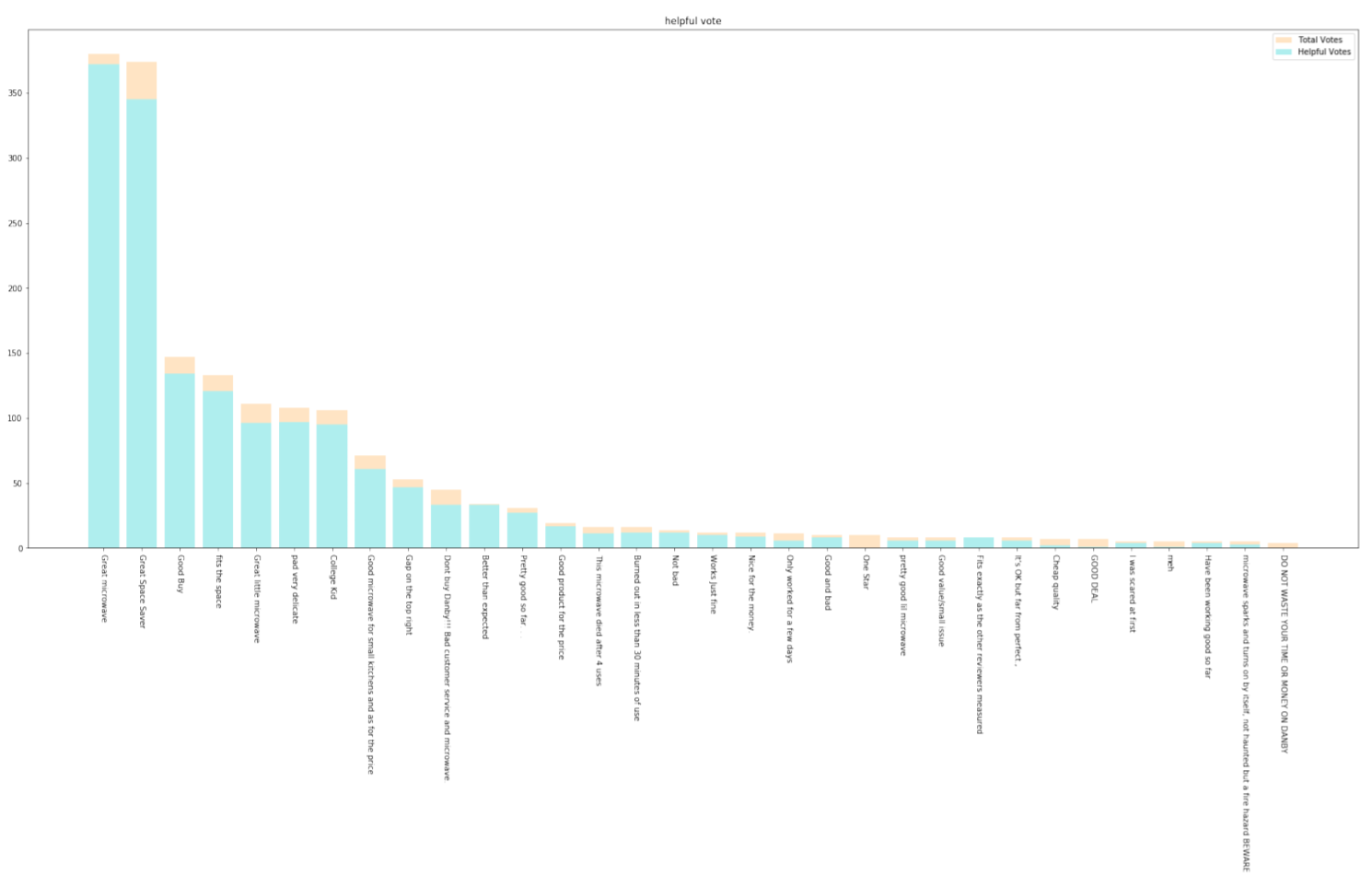
Figure 6: The Reviews' Total Votes and Helpful Votes of Danby 0.7 cu.ft. Countertop Microwave
Model Construction
In the previous data preprocessing, we have processed a series of reviews_text through the Tokenization algorithm. Next, we will process the data through the TF-IDF (Term FrequencyInverse Document Frequency) algorithm and the MLP (Multi-Layer Perception) model to get the relationship between star_rating and review.
The keywords in different product reviews are quite different and will affect each other, so we build three prediction models for the products: microwave, pacifier, and hair dryer. We first use the TF-IDF algorithm to obtain the term frequency matrix. TF-IDF is a commonly used weighting technique for information retrieval and data mining. The algorithm can simply and efficiently find keywords in articles.
Compute the TF-IDF Matrix
TF-IDF consists of two parts, one is “Term Frequency” (abbreviated as TF), and the other is “Inverse Document Frequency” (abbreviated as IDF).
TF part will create a Term Frequency Matrix. We use the review_text in Figure 1 to
illustrate the process. The procession is shown in Figure 7.

Figure 7: TF Procession
In Equation 1, \(f_i\) is the frequency of the \(i\)th word. \(c_i\) is the occurrence number in a review_text of the ith word. s is the amount of words in the review_text. we find out that in Figure 7 the word frequencies of ’look’, ’good’ and ’long’ are the highest. However, this does not mean these three words are equally important in the analysis process. We need to multiply this word frequency matrix by IDF (Inverse Document Frequency) to get the TF-IDF values of these words.
In Equation 2, \(d_i\) is the IDF value of the ith word. \(m\) is total number of articles in Corpus. \(n_i\) is the number of articles containing the ith word in Corpus. \(v_i\) is the TF-IDF value of the \(i\)th word.
We give Figure 8 as an example for the TF-IDF values. After that, we will construct the TF-IDF matrix of the review based on the TF-IDF values of these words corresponding dictionaries. It is worth mentioning that we apply helpfulvotes as a reference to the TF-IDF matrix. In Equation 4, \(M\) is the TF-IDF matrix for the product. The \(k\)th review’s \(i\)th word’s TF-IDF value is \(v{ki}\).

Figure 8: TF-IDF Values
Construct the MLP Model
We divide three data sets into training sets and test sets by a ratio of 3:1 respectively. Then we use the input and output of the training set to train MLP(Multi-Layer Perception). The core formulas of the MLP are show below.
Multi-Layer Perception made up of a lot of artificial neurons. The artificial neuron uses a nonlinear activation function to output an activity value.The training process of MLP can be divided into the following three steps:
- Calculate the state and activation value of each layer, until the last layer;
- Calculate the error of each layer by backward propagation;
- Calculate the partial derivative of each layer’s parameters, and update the parameters.
Suppose neurons accept our TF-IDF Matrix \(X = (x1, x2, . . . , xn)\). State \(z\) is used to represent the weighted sum of input signal \(x\) obtained by a neuron, and the output is the activity value a of the neuron, which is defined as follows:
In the process of forward propagation, we use notations as folloowing Table 4.

In the process of back propagation, given a set of samples \((X(i), y(i)), 1 ≤ i ≤ N\), the output of feedforward neural network whose objective function is \(f(X(i)|W, b)\) is as follows.
We use gradient descent to minimize the Equation 9, finally we get \(l\)th layer’s error in Equation 11.
Then we continue to iterate and get an error-stable model. Finally, we use the trained model to predict the test data. We set the fitting figure of Microwave in three products as Figure 9.
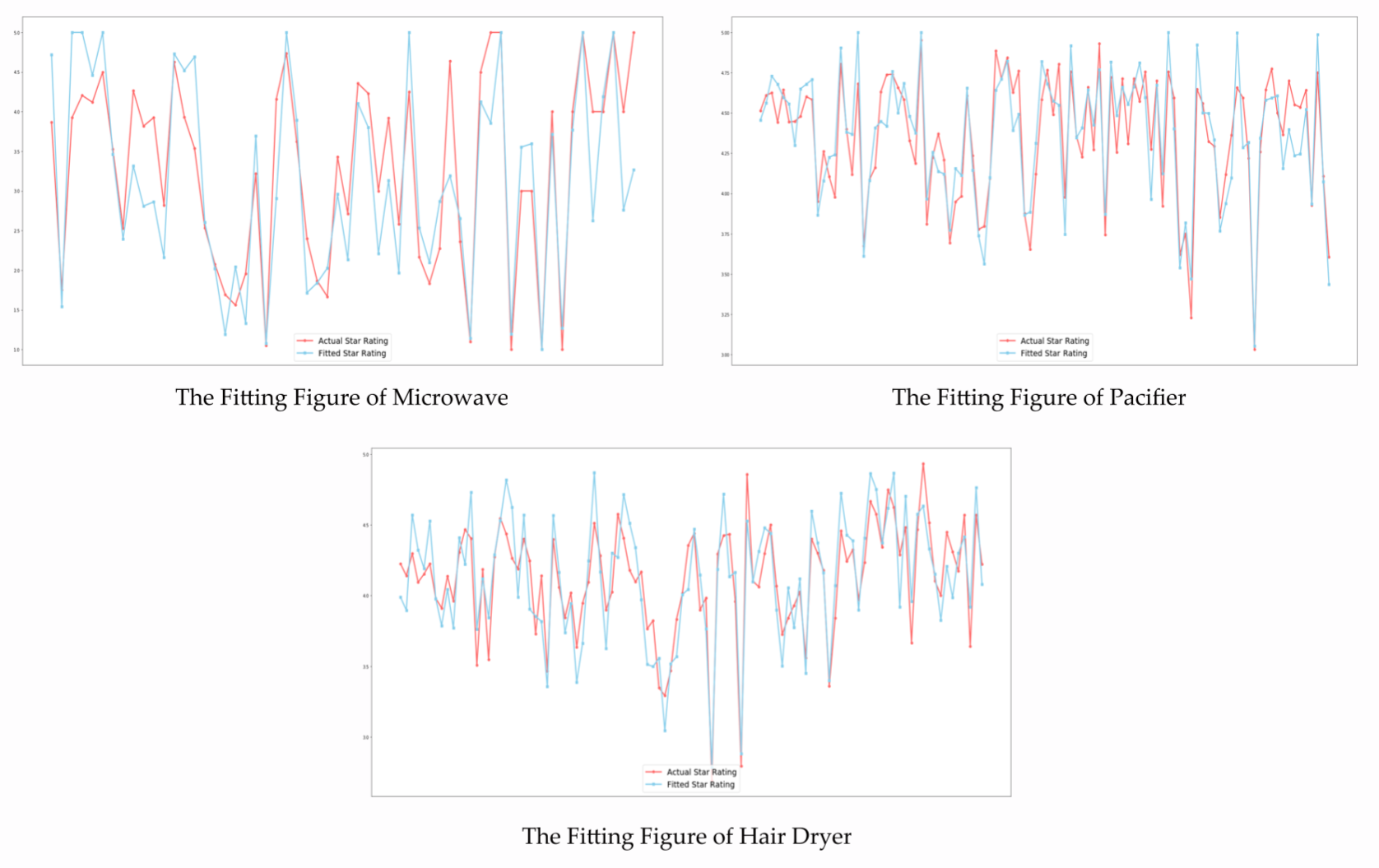
Figure 9: The fitting Figure of Hair Dryer
Time-Based Analysis
Product reputation is composed of star rating and popularity. Product quality is the determing factor of star rating and review content. We will analyze popularity based on time to provide suggestions for sunshine company.
We analyze the 8 products with the highest popularity, and observed their popularity changes over time. It can be seen from the Figure 10 that five of the eight products have peak popularity only at the beginning of each year, and the other three products will have peak popularity at the beginning and middle of each year. There are three reasons for this:
a. At the beginning of the year, it’s just the time for people to purchase in the new year. People’s desire for shopping is strong, while microwave, pacifier and hair dryer are durable products, which can be used for a long time. No one will buy twice in a short time.
b. Amazon or merchants have promotional activities at the beginning of the year to improve product popularity.
c. The data retrieving process is not objective, we only get the data at a certain period.
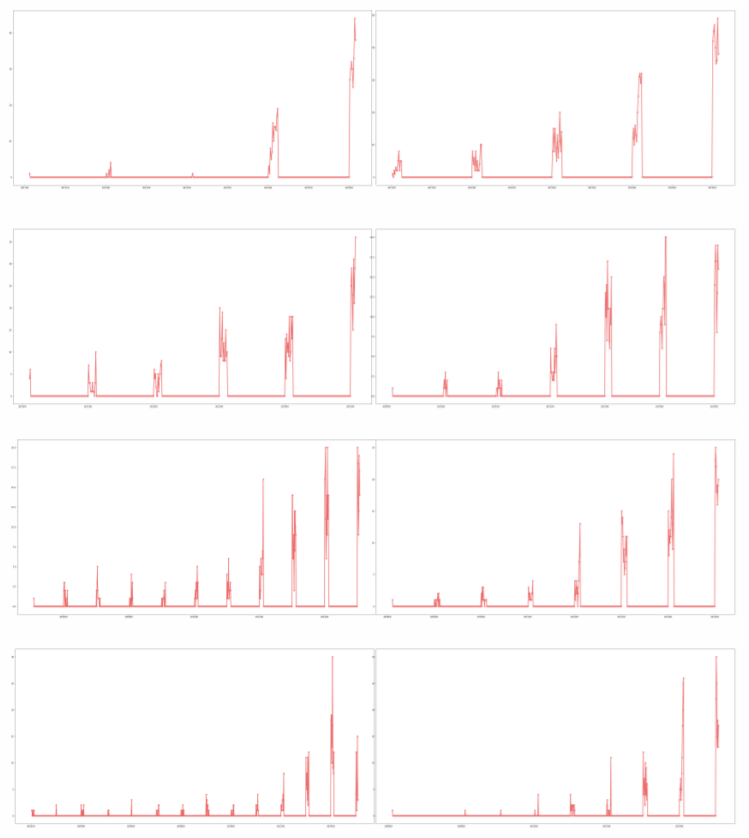
Figure 10: The Number of Reviews of the 10 Most Popularity Products
A products reputation consists the product’s praise and popularity, and the decisive factor that influences a products star ratings and the content of its reviews is its quality. In the following discussion we will offer a proposal for Sunshine Company from the perspective of the products popularity.
We analyze the top eight popular products and observe their popularity changes over time. To our surprise, 5 of these 8 products have popularity peaks only at the beginning of each year, and the remaining three products have popularity peaks at the beginning and middle of the year. There why This phenomenon happens are as follows:
- In the beginning of the year, everyone is buying goods for the coming of new year. So people’s desire for shopping is strong. On the other hand, the microwave, pacifier and hair dryer are all durable commodities, which can be used for a long time. So there will be no repurchase in a short time. Therefore, there will be peaks of popularity in only particular times.
- Amazon or sellers have promotional campaign at the beginning of the year in order to increase the products popularity.
- The data collection process is not objective. Only data of the beginning and middle of the year were collected.
Sales Strategy
Our goal is to allow Sunshine Company to expand market influence, continuously improve products and win a good corporate reputation among the public. We will make recommendations for Sunshine Company from two perspectives: How to Enhance the Reputation and How to Improve the Product.
How to Enhance the Reputation
Reputation consists of two parts: popularity and star rating. First of all, from the perspective of popularity, we hope more people could pay attention to the company’s products. The most direct way to do this is to choose the right time to advertise and promote this product. we recommended that Sunshine Company are supposed to enhance propaganda and increase the discount at the beginning and middle of each year to increase product sales and popularity.
How to Improve the Product
On the other hand, for Star rating, the most fundamental influence of it is the product itself. By analyzing the content of the review, we could comprehend the relationship between star rating and review, furthermore, we could improve the product through the content review. Therefore, analyzing the content of the review is of vital importance.
From the previous model, we believe that there are three types of customers that worth pay attention to. Their reviews and attitude towards the product can effectively help us to improve the product.
- Amazon Vine Voices Members
These people are selected by Amazon. They are the most trusted reviewers on Amazon to post opinions about new and pre-release items to help their fellow
customers make informed purchase decisions.
- People who have bought a lot of different products.
These people have experienced more similar products than common customers, and they have a deeper understanding of this type of product. We have selected
nine such customers for Sunshine Company, their reviews are in the appendix.
- One-star rating customer
our products or services may not meet the needs of all customers, so some of these customers give a one-star rating. Compared with five-star users who have very low-information reviews, these one-star rating users often directly mention the shortcomings of the product. So It is often helpful to look at these reviews
carefully.
we give the word cloud of one-star rating user of the microwave reviews below. There are words such as “service” and “warranty” in the word cloud. So we conclude that these users are dissatisfied with the product services and product warranty of the
microwave. In this way we can make specfic measures toward this issue. The word cloud of one-star rating users reviews by Pacifier and hair dryer is in the appendix. At the same time, we can find that users who give one star and users who give five stars tend to have more emotional reviews.
Conclusions
Sunshine Company want to launch three new products in online marketplacemicrowave, pacifier and hair dryer. And they hire our team to help them to analyze the relevant products in the current market and make suggestions for their product sales.
At first,we process the dataset.We delete some data with missing values.At the same time,we find some data of click farmers.We also remove these useless data.We screen and integrate 15 attributes of the data set,leaving 11 basic attributes and 3 synthetic attributes.For a large number of texts in the review,we use the tokenization algorithm to cut the complex texts into simple words for our subsequent ananlysis.
Then,we analyze and visualize the attributes of the data set.In this way,we have a full understanding of the whole data set. We use the multi-demension evaluation system of “reviews evaluation products” and “helpful votes evaluation reviews”, through TF-IDF technology and MLP model to analyze the relationship between star rating, review and helpful votes,to help sunshine company to have a deeper understanding of products in the market.
Finally,on the basis of time ,we analyze the product heat,get a deeper understanding of customer review ,and provide a way for sunshine company to increase its products’popularity.
Strenghths and Weaknesses
Strengths
- Our model has strong interpretability
The traditional MLP model has poor interpretability,and we continue to do lexical analysis and grammatical analysis on this basis, which enhances the interpretability of the whole model.
- We look at the product from the customer’s perspective
We analyze the user’s emotion and build the user’s portrait through the user’s comments. At the same time, we find some customers who are meaningful to sunshine company.
Weaknesses
- There is a lack of analysis at the time level.
At the time level, we only analyze the changes of product popularity, and there are a lot of contents that can be mined between time and review.
- We don’t build relationship among the three products.
If our model can fully break the sales relationship among the three products in the market, it will be more helpful for sunshine company which sells the microwave, pacifier and hair dryer at the same time.
Appendix: Product Profile
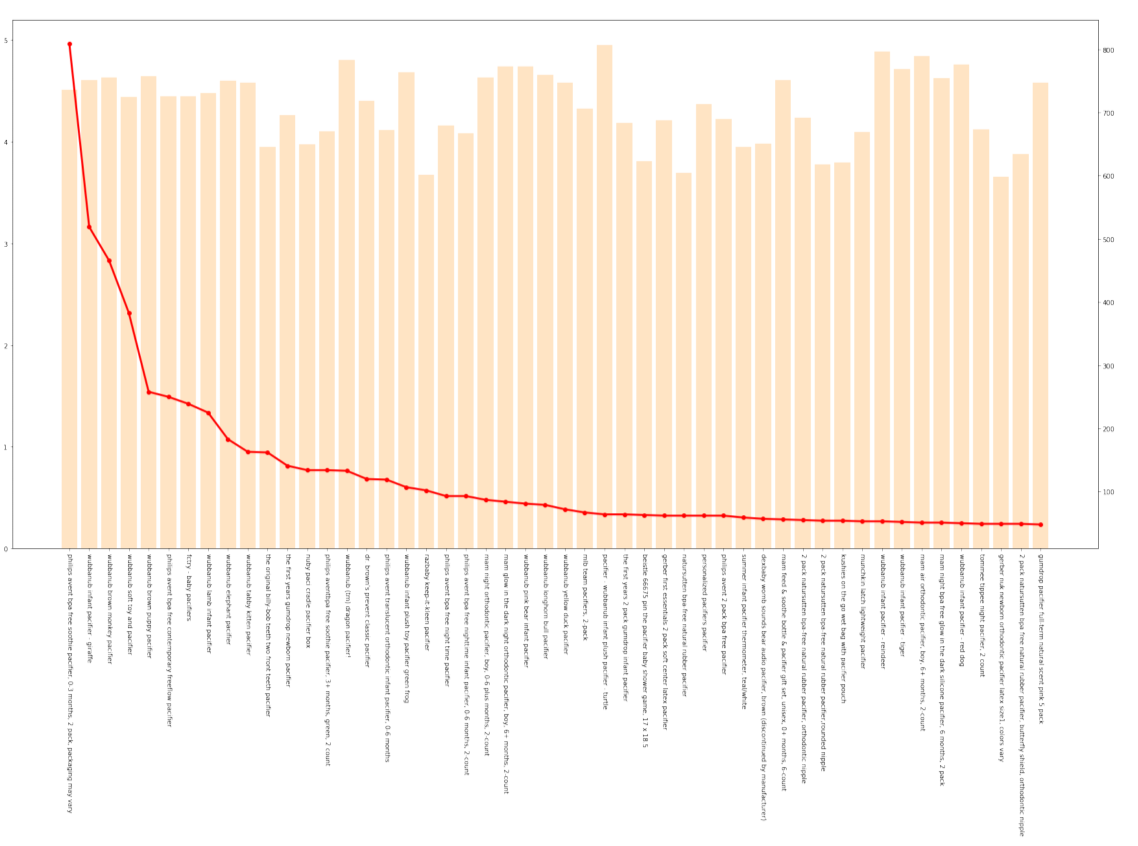
Figure 11: The Star Ratings and the Number of Reviews of Pacifier
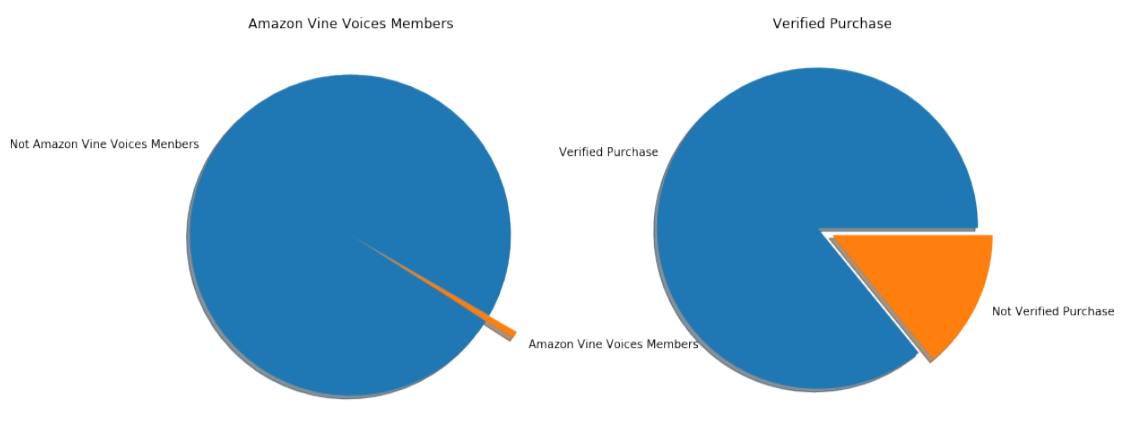
Figure 12: The Proportion of People Who Were in Amazon Vine and People Who Had Bought the Product
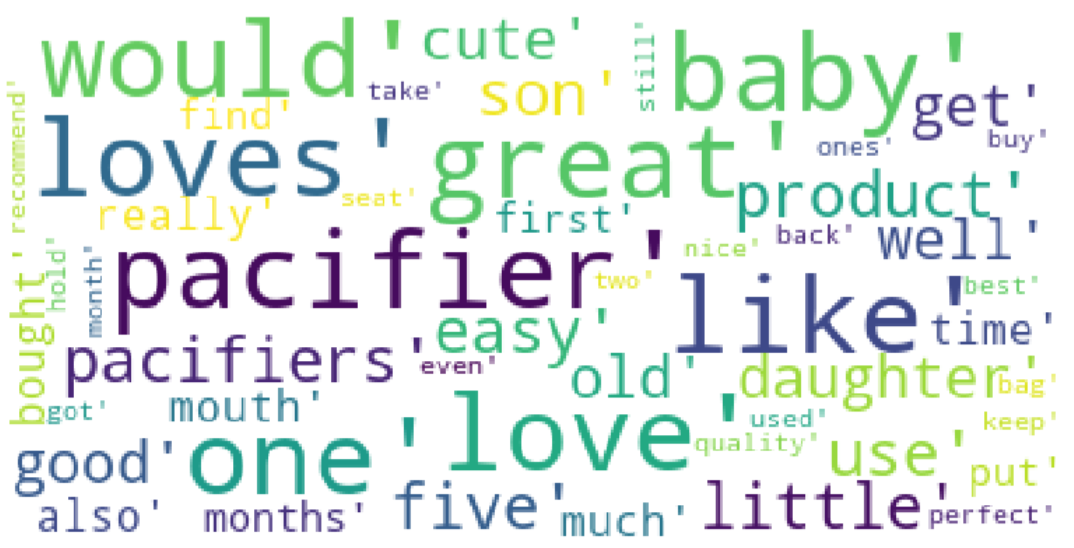
Figure 13: The Wordcloud of Pacifier
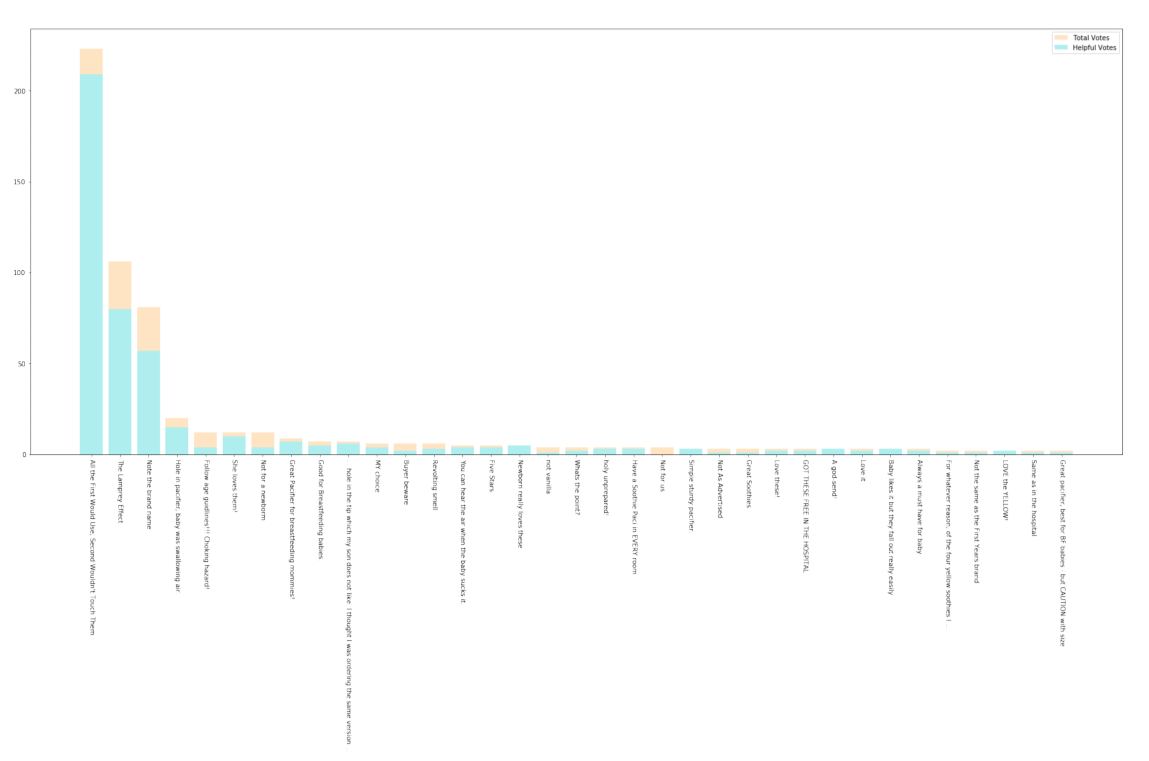
Figure 14: The Reviews’ Total Votes and Helpful Votes of a Pacifier Product
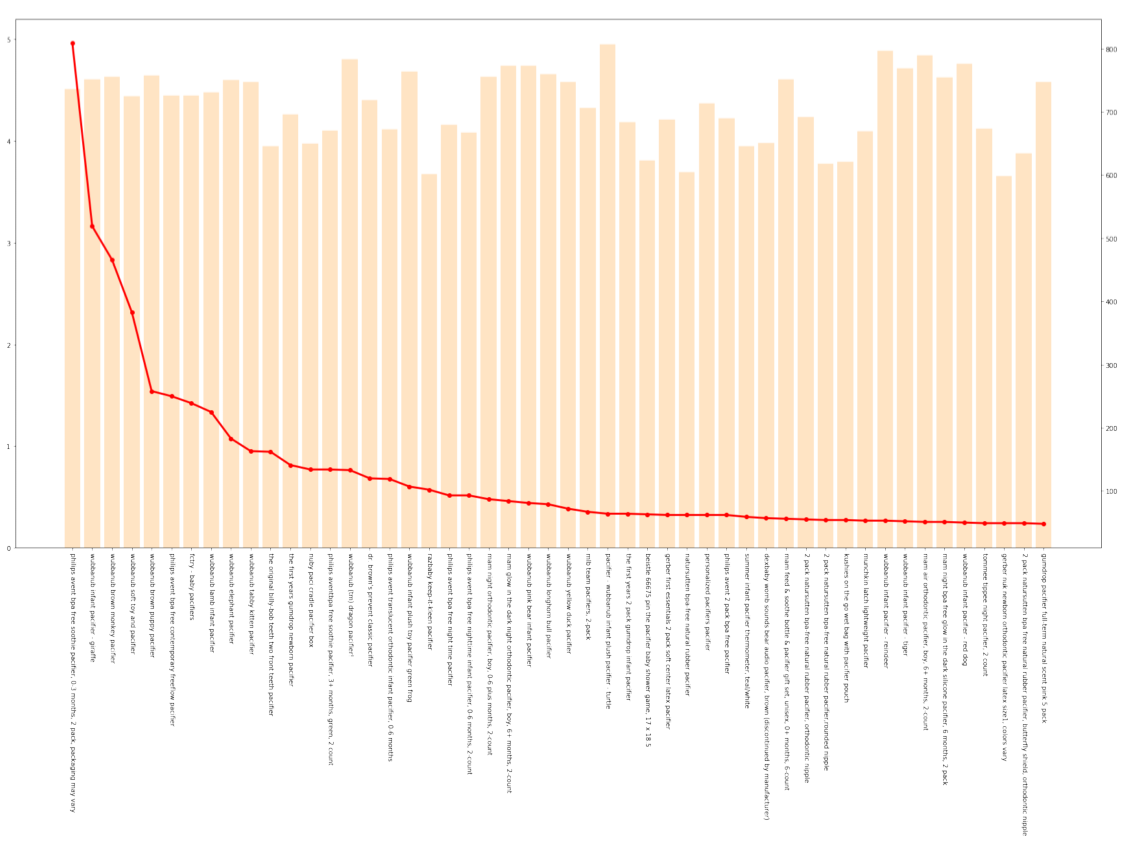
Figure 15: The Star Ratings and the Number of Reviews of Pacifier
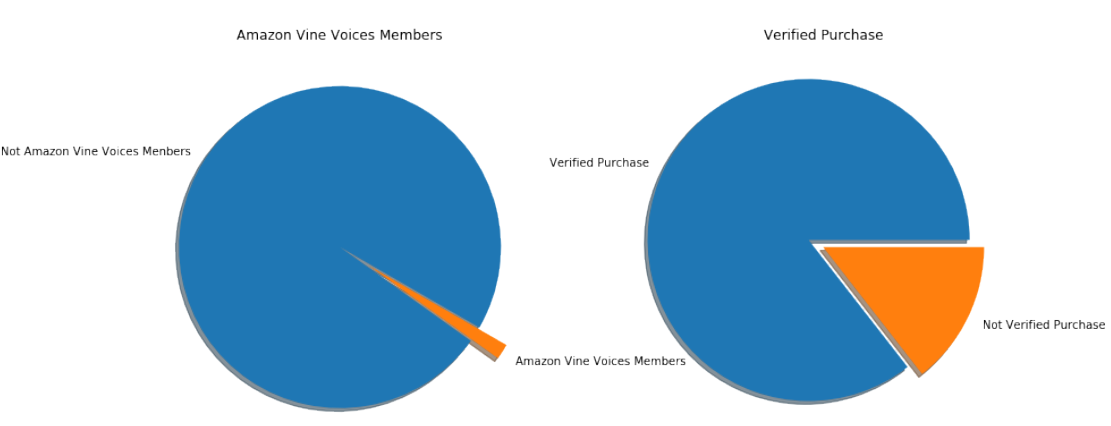
Figure 16: The Proportion of People Who Were in Amazon Vine and People Who Had Bought the Product
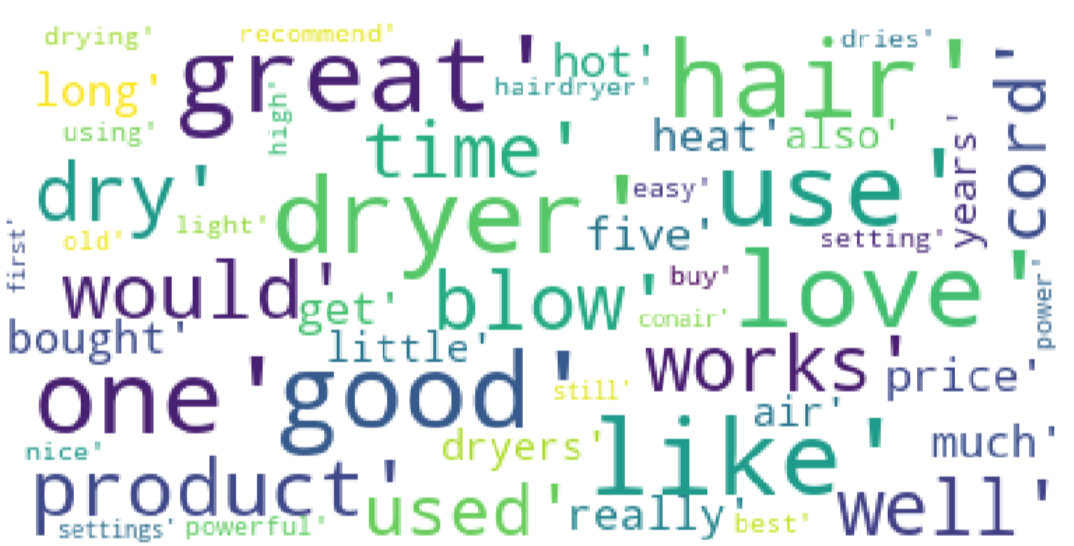
Figure 17: The Wordcloud of Pacifier
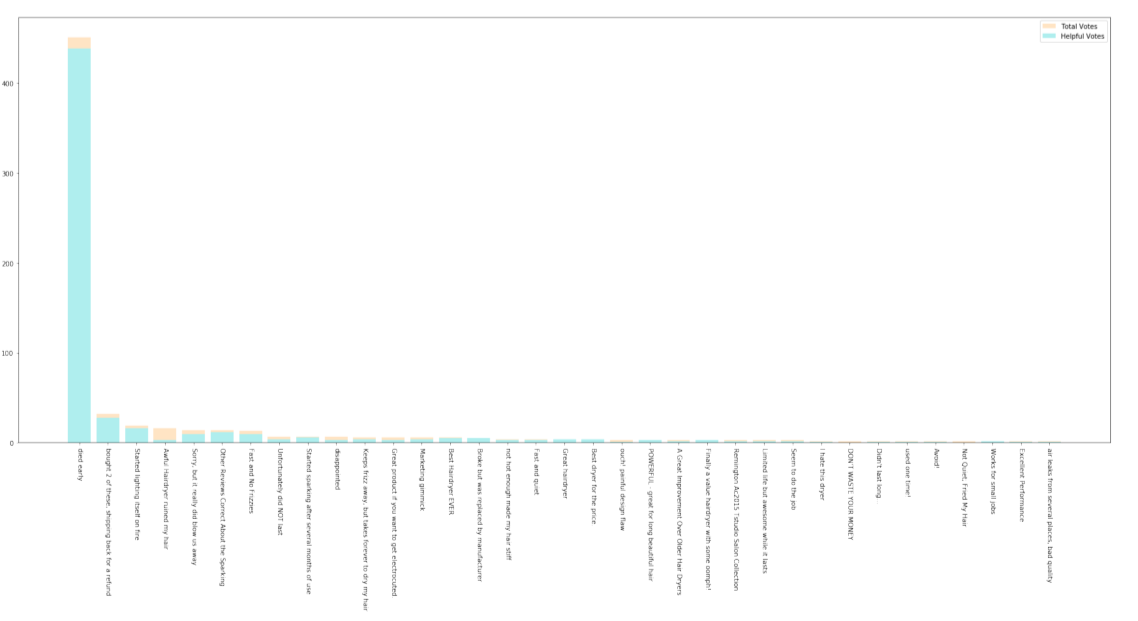
Figure 18: The Reviews’ Total Votes and Helpful Votes of a Pacifier Product
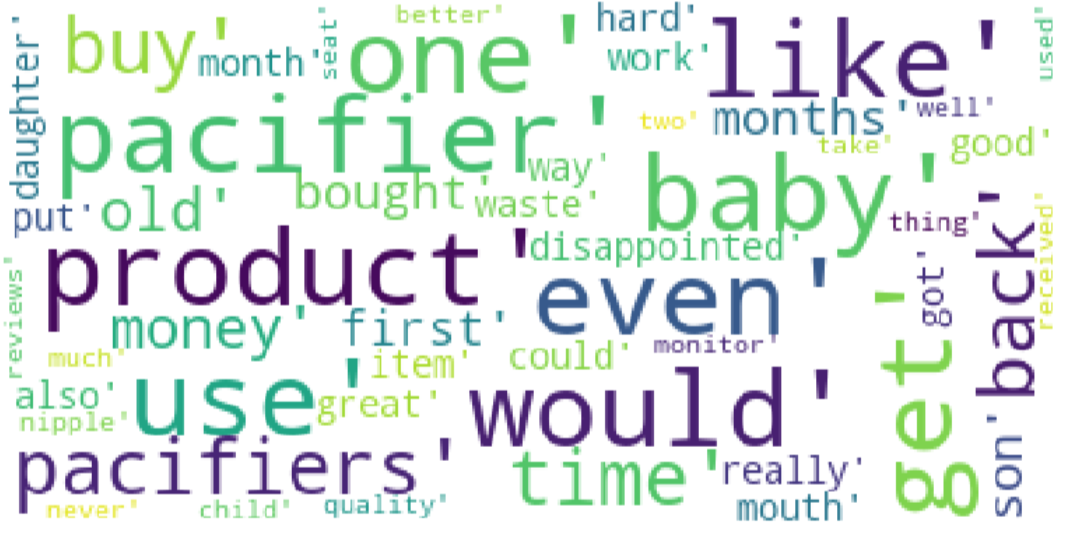
Figure 19: The WordCloud of Reviews with One Star about Pacifier

Figure 20: The WordCloud of Reviews with One Star about Hair Dryer