Sentiment Analysis | Netizen Sentiment Recognition During COVID-19
The emergence of the COVID-19 has disrupted our normal life. People’s psychological state can also receive a great negative impact. We chose such a topic with humanistic concern in Data Warehouse and Data Mining course, hoping that through Weibo posts we can gain more insight into people’s emotional state during the COVID-19. We are awarded the best project (1/23) in this course, and we think we could do more in psychological care during COVID-19.
Data Source and Data Structure
This data comes from a data mining competition organized by DataFountain. The data set is a collection of Weibo crawled during the COVID-19. The link to the dataset is here.
The dataset cannot be downloaded directly from the official website because the competition has ended, the dataset can also be found on Kaggle.
We used 100,000 posts from the training set provided by the competition website, but considering the time and computational cost, I only used the first 10,000 posts with annotations, and divided them into a training set and a test set in a 7/3 ratio. This dataset was based on 230 keywords related to the topic of “新冠肺炎”, which means COVID-19 in Chinese.
1,000,000 Weibo posts were collected from January 1, 2020 to February 20, 2020, and 100,000 Weibo posts were labeled with three categories: 1 (positive), 0 (neutral) and -1 (negative). The data is stored in csv format in nCoV-100k.labeled.csv file. The original dataset contains 100,000 user-labeled posts in the following format: [post id, posting time, posting account, content, photos, videos, sentiment].
The original dataset has six attributes: post id (hashcode), posting time (Date), posting account (String), content (String), photos (String), and videos (String). Predicting sentiment(Int) by the above attributes. The purpose of this project is to use word bag preprocessing, TF-IDF preprocessing, word2vec and compare their effects, focusing on text processing and text sentiment analysis. So we only chose content attribute to predict the sentiment. (It was hard for us to read the emotion from photos and videos.)
Here is the statistical information of the dataset from Kaggle.
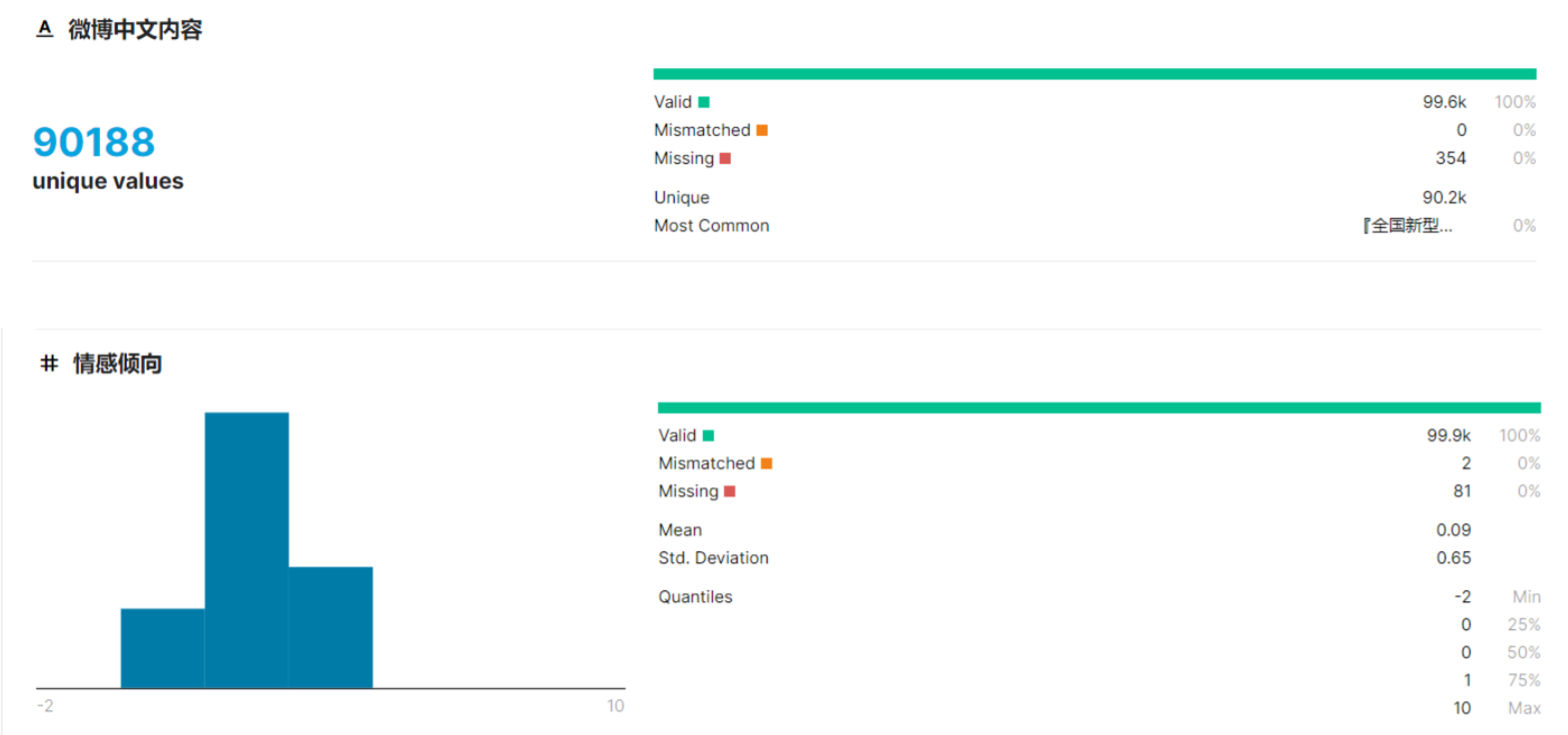
The bar chart shows that the number of positive, neutral and negative posts varies considerably, with the highest number of neutral posts.
Here is the first post in dataset.
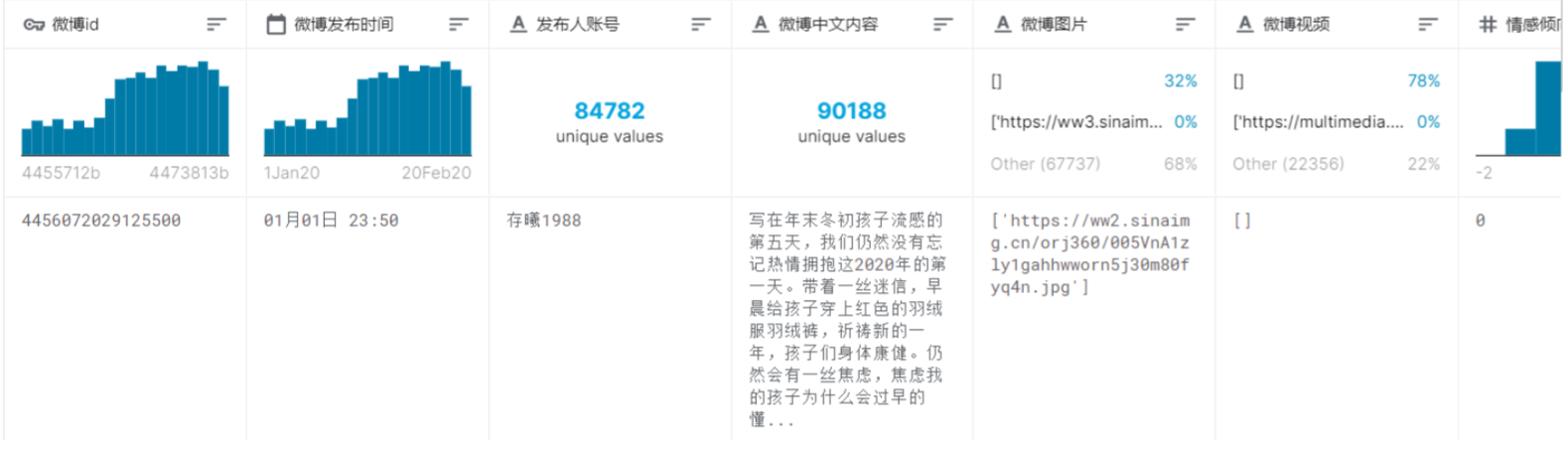
We found this posts in Weibo APP.

Data Preprocessing
We Used Kaggle Kernel. Kaggle provides free access to the Nvidia K80 GPU in the kernel. This benchmark shows that using the GPU for your kernel can achieve a 12.5x speedup in the training of deep learning models.
Data import and turncut
import pandas as pd filepath = '/kaggle/input/chinese-text-multi-classification/nCoV_100k_train.labled.cs v' file_data = pd.read_csv(filepath) |
Handling missing values
# handling missing values |
Remove meaningless symbols
import re |
Word Cut
# word cut |
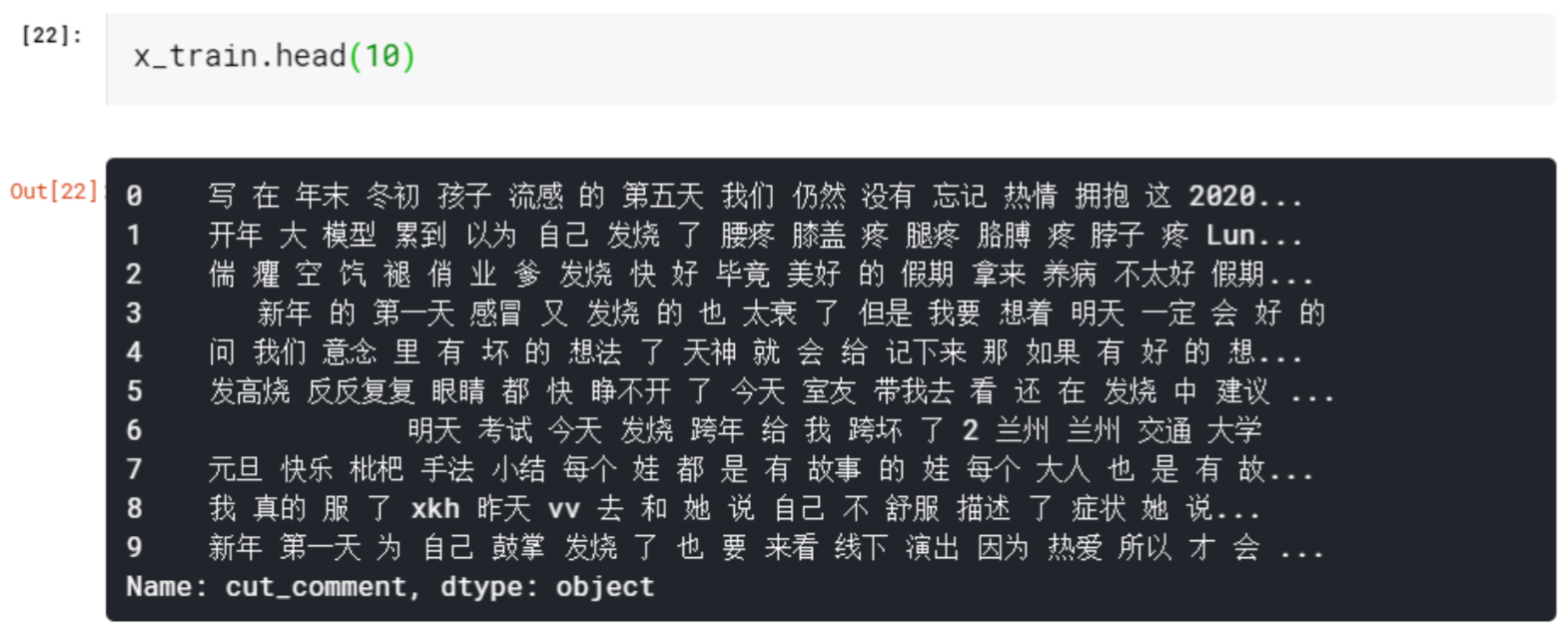
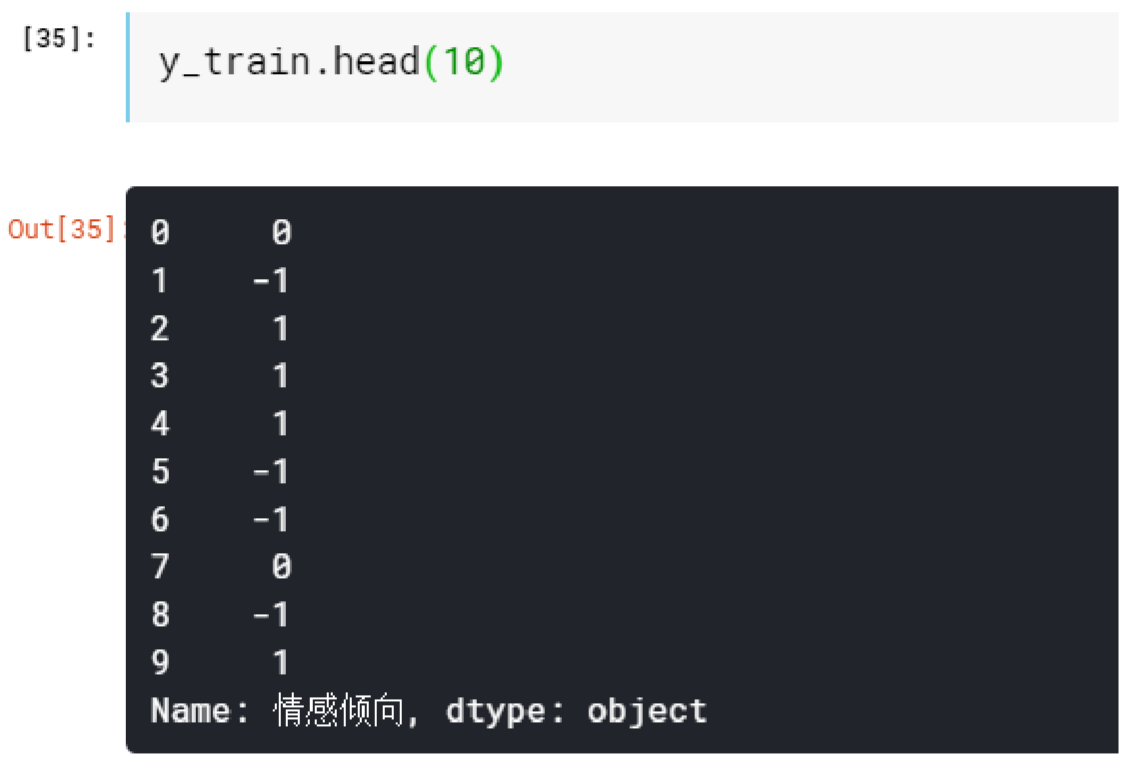
Import Stop Words
# import stop words |
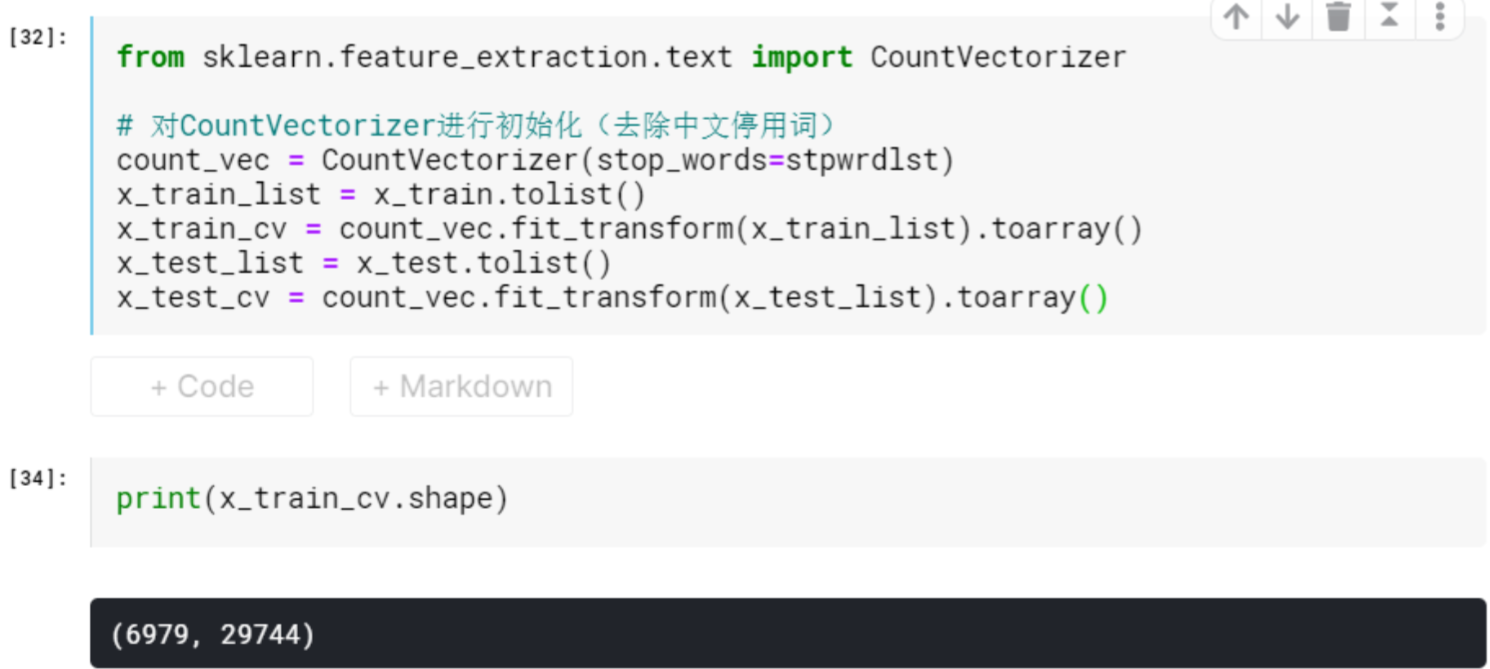
Word Bag Preprocess
from sklearn.feature_extraction.text |
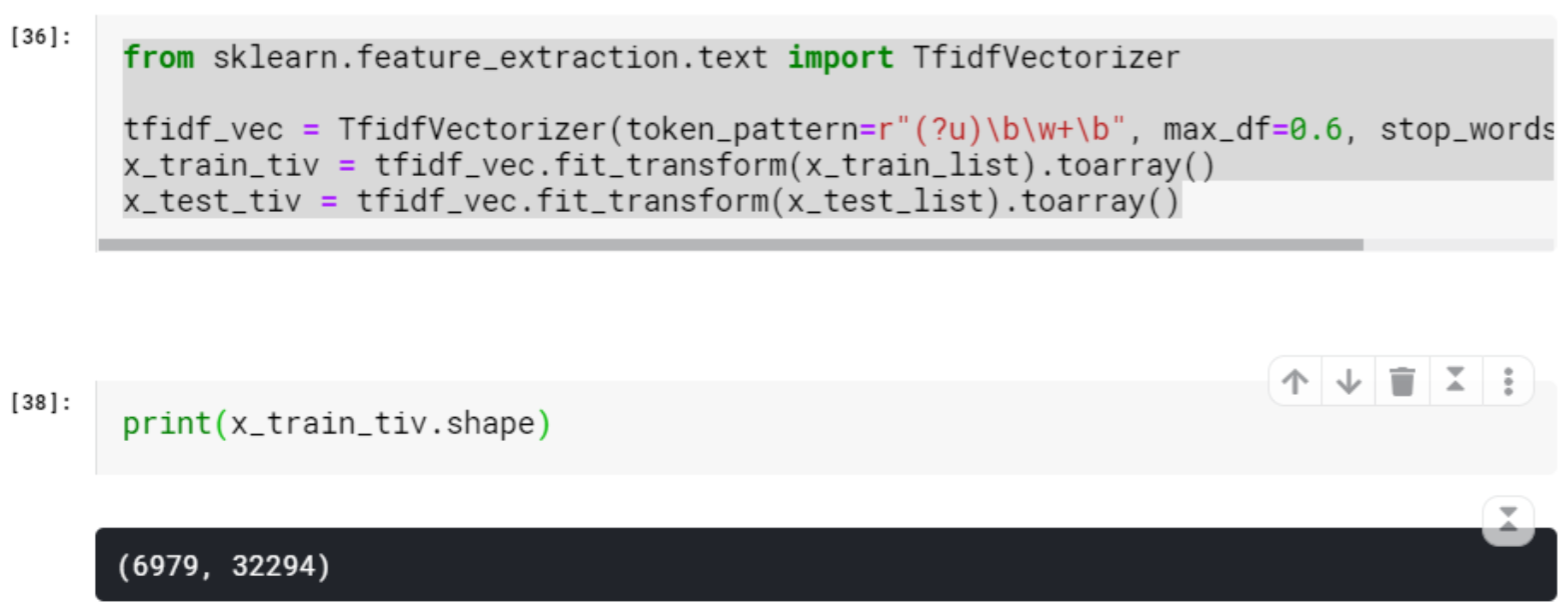
TF-IDF Preprocess
from sklearn.feature_extraction.text import TfidfVectorizer |
word2vec embedding
# word2vec |
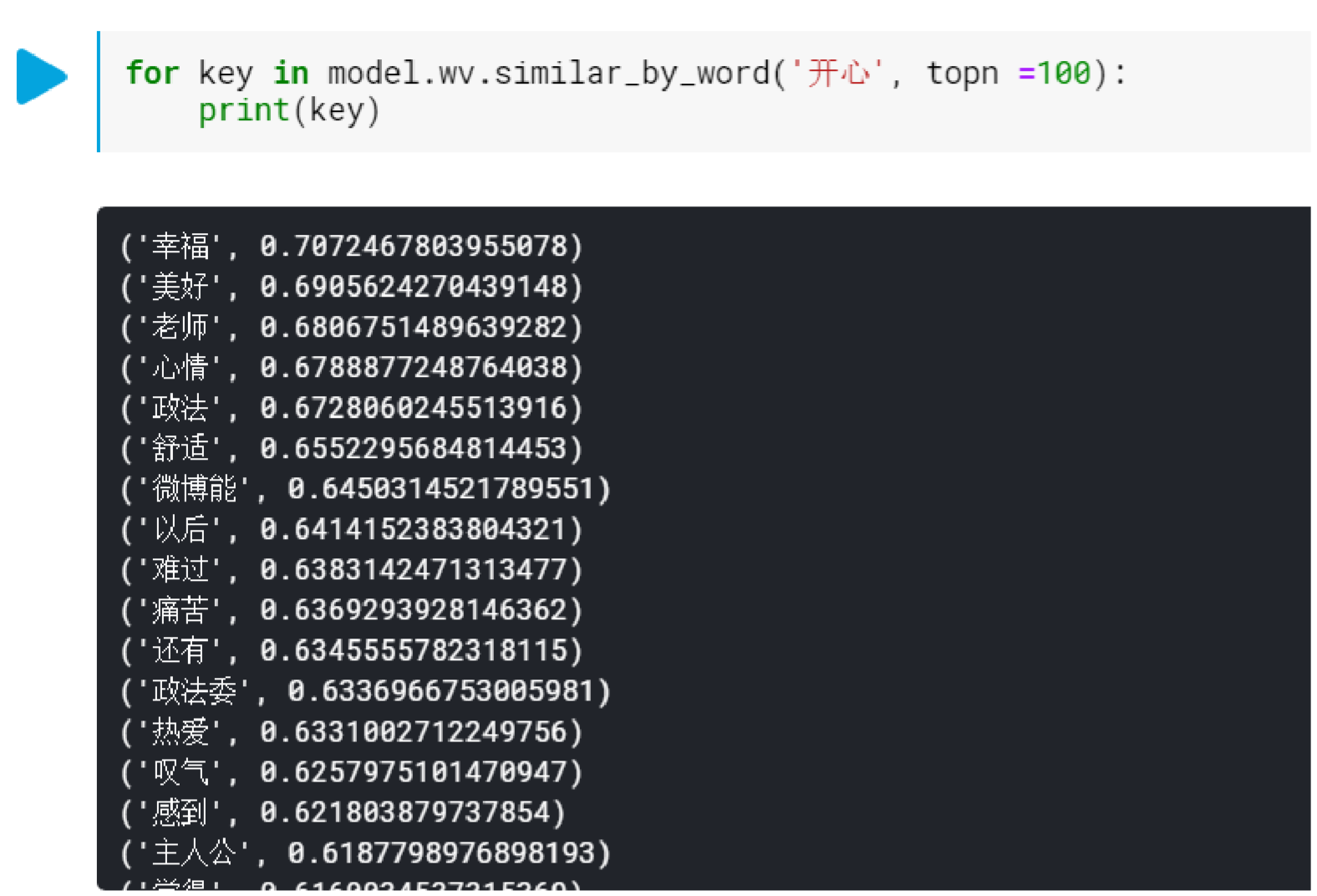
The corpus of 10,000 training data is still a bit small, but the results are slightly more productive. For example, if we look at the close synonyms of “开心”(happy), we can see that the results returned are more positive.
Data Mining Algorithm
In this section, we will use SVM, decision tree and RNN algorithms to achieve classification. The embedding obtained by BOW and TF-IDF will be classified by SVM and decision tree algorithms, respectively, while the embedding obtained by Word2Vec will be classified by RNN.
The embedding obtained from Word2Vec will be classified using RNN. The detailed algorithm flow is as follows.
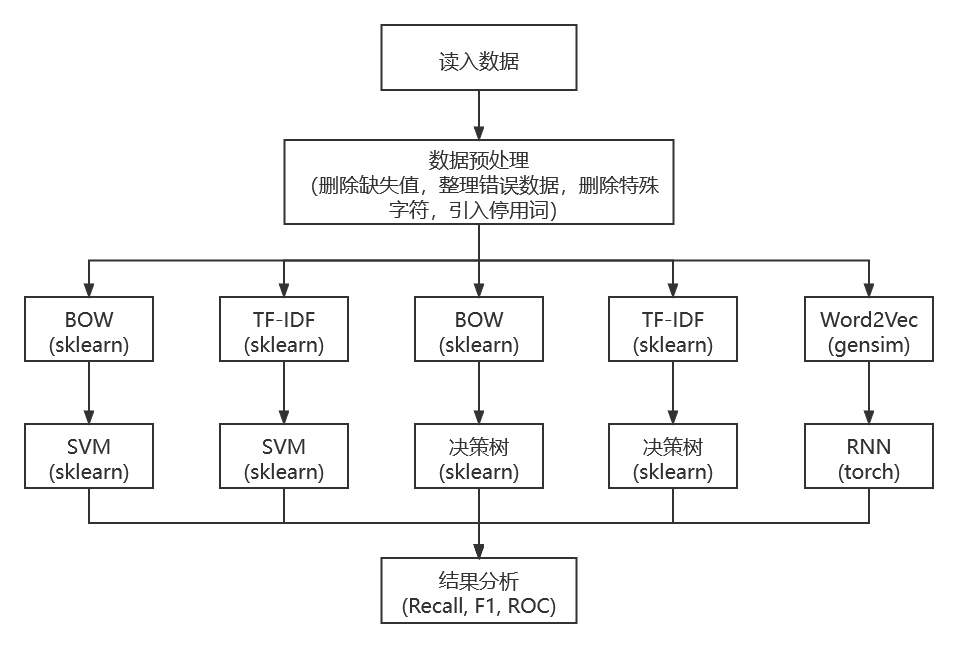
BOW + SVM
The 35596-dimensional embedding of the Weibo posts obtained by BOW is used as the input of the SVM in the sklearn package.
The parameters are as follows.
clf = svm.SVC(C=0.8, kernel='rbf', gamma=20, decision_function_shape='ovr') |
from sklearn.preprocessing import StandardScaler |
TIPS:
SVMandDecision Treealgorithms for 10,000 of 30,000-dimensional data can take a lot of time, and sklearn does not support GPU computing.- When you encounter a very large dataset, you should first use a small demo to check the correctness of the code, and then run a large demo with a large amount of data.
BOWandTF-IDFshould be used first before dividing the test and training sets, otherwise the test and training sets will not have the same dimensionality! It took a lot of time to fix this error.- Due to the excessive number of dimensions, remember to normalize the data before
SVM.
# prepare the data |
#test bow+svm |
from sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score |
# roc_curve:真正率(True Positive Rate , TPR)或灵敏度(sensitivity) |
Here’s the result:
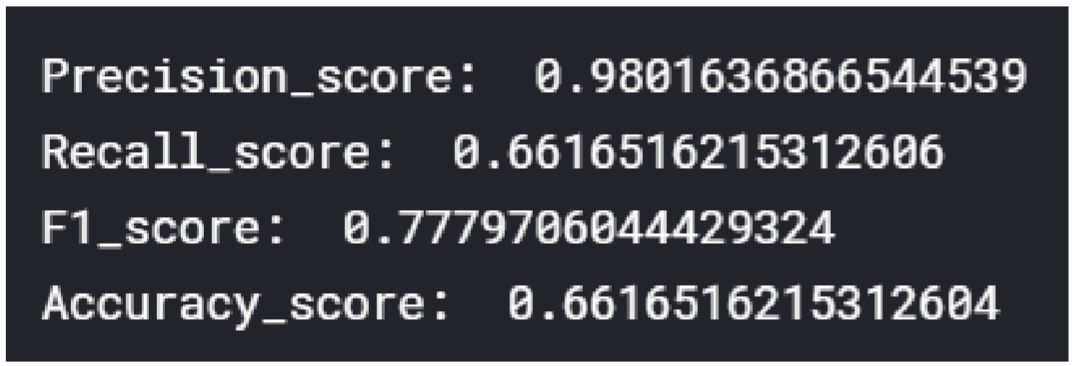
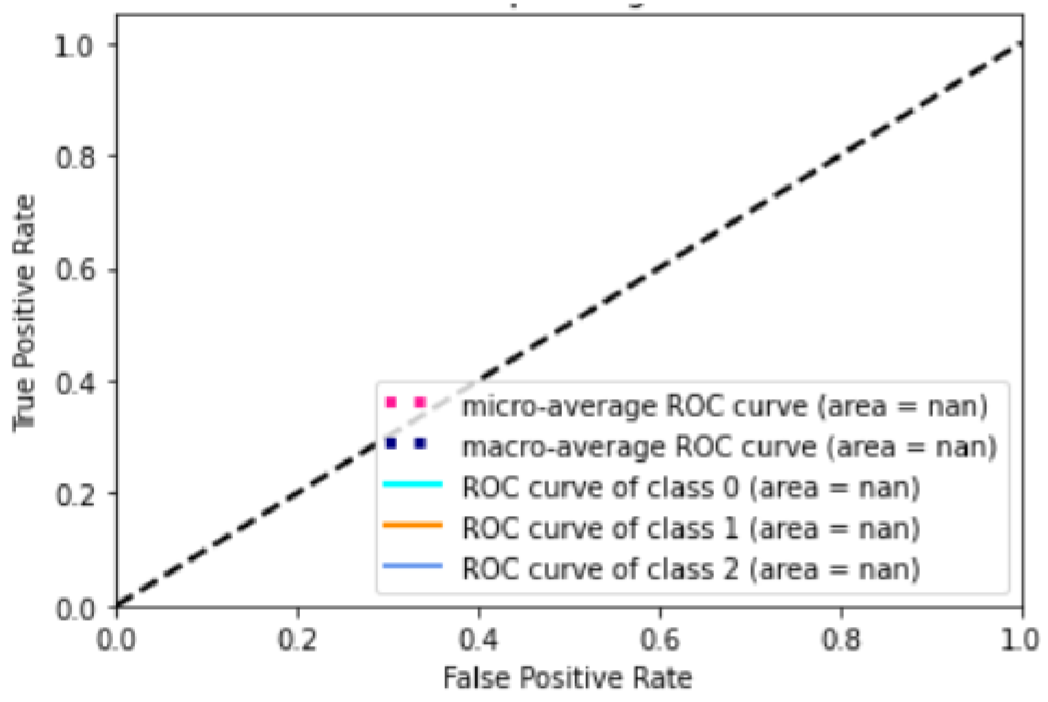
The reason for the coincidence of the ROC curve and the X-axis is that most of the predictions are zero. The reasons are as follows:
- The two embedding methods,
BOWandTF-IDF, do not work well asSVM, and even after normalizing the input word (frequency) vector matrix, most of the predictions are still the same. - The number of “neutral” labels in the sample is much higher than the number of “positive” and “negative” labels, which is also a problem in the sample selection process.
- The parameters of
SVMcan be adjusted more precisely to make the classification better.
Instead of further tuning this model, we tried other algorithms first.
TF-IDF+SVM
The 38473-dimensional embedding of the TF-IDF derived posts is used as the input to the SVM in the sklearn package.
The source code is similar to the model above, so I will not repeat it here. The results are shown below.
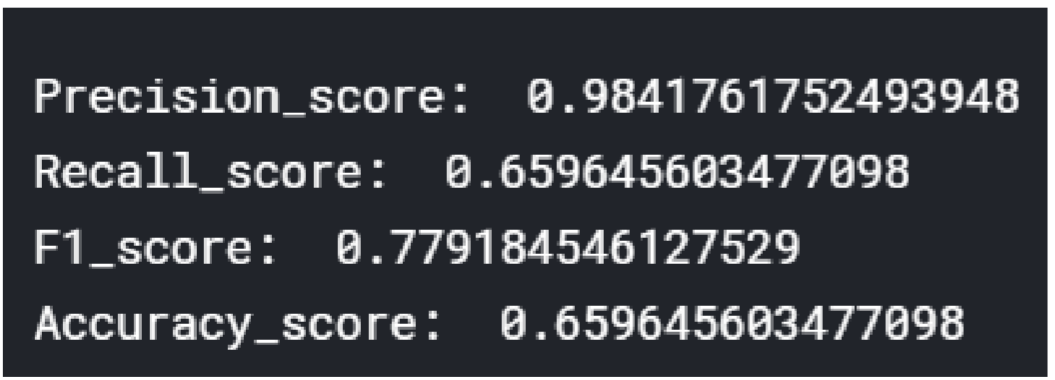
The parameters are as follows.clf = svm.SVC(C=0.8, kernel='rbf', gamma=20, decision_function_shape='ovr')
BOW + Decision Tree && TF-IDF + Decision Tree
The source code is similar to the model above, so I will not repeat it here.
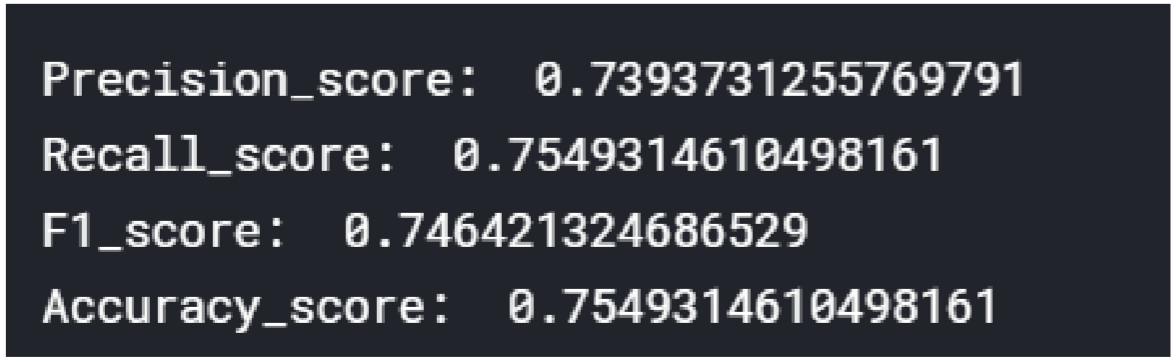
Here’s the result for BOW + Decision Tree.
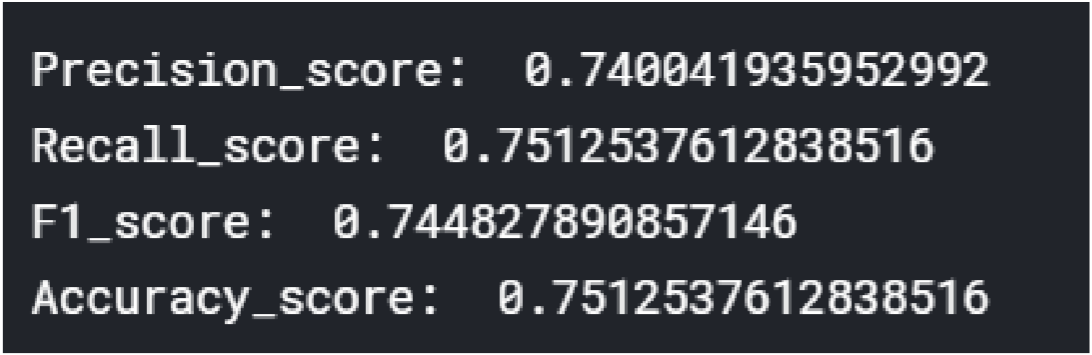
Here’s the result for TF-IDF + Decision Tree
Word2Vec + RNN
Embedding Weibo content using Word2Vec, then the resulting 400-dimensional vector is fed into a 102001 recurrent neural grid with one hidden layer.
Parameters:batch_size = 100
n_iters = 20000
seq_dim = 20
input_dim = 20 # input dimension
hidden_dim = 200 # hidden layer dimension
layer_dim = 1 # number of hidden layers
output_dim = 3 # output dimension
So far we have obtained the embedding of all words, the key problem is how to represent the sentences. I referred to the information below and chose to try it with word2vec using Gensim.
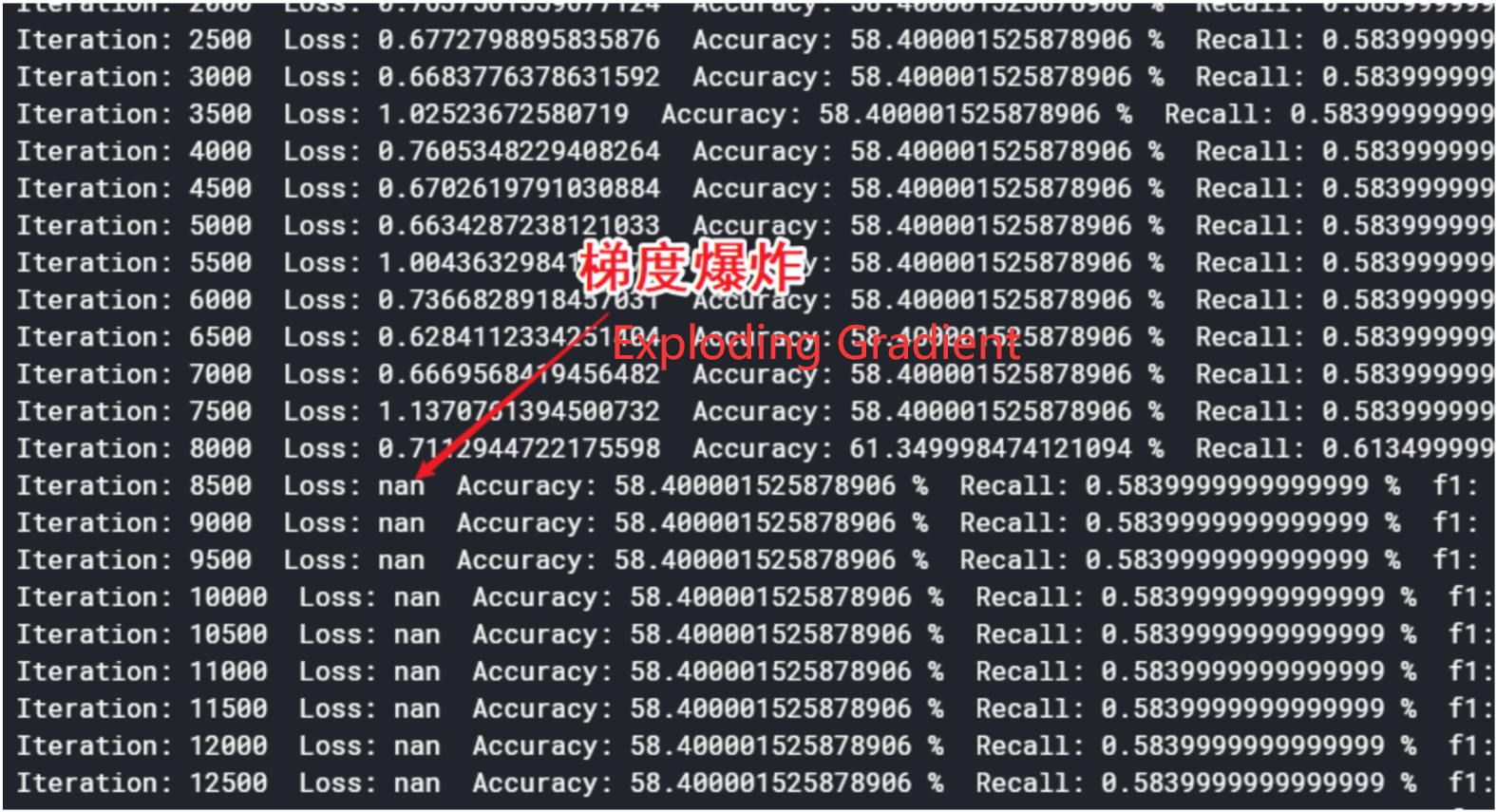
At the first time we try, there is exploding gradient.
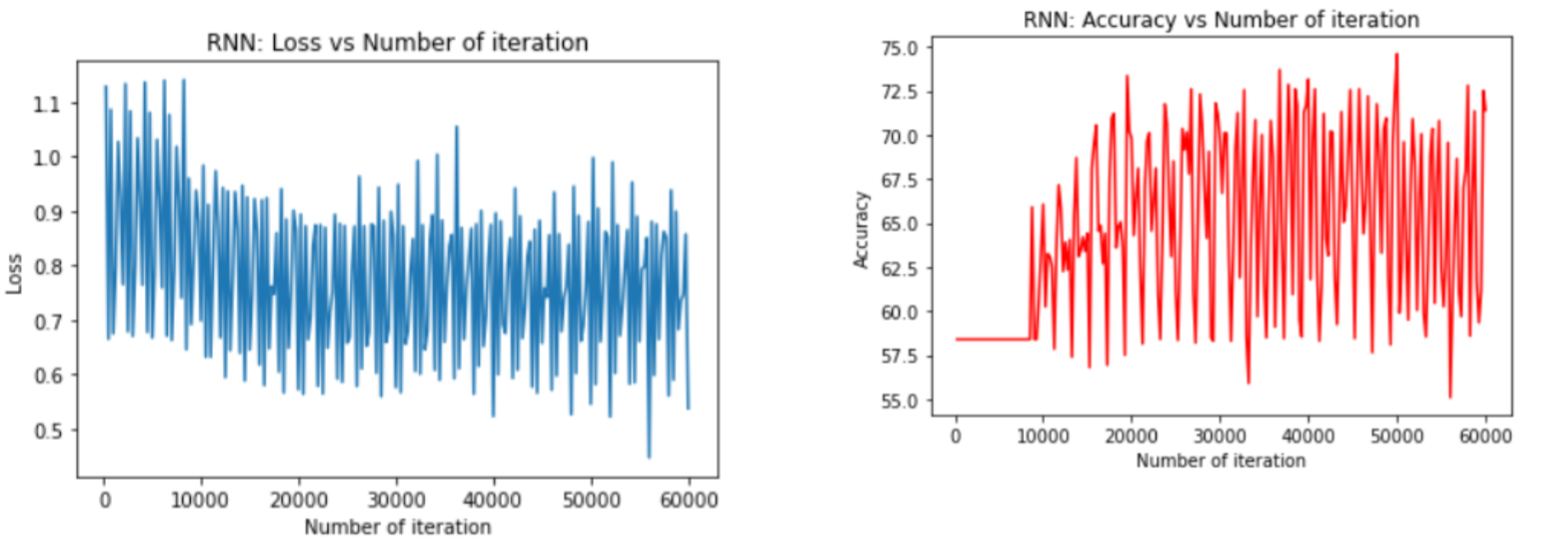
After adjusting the learning rate to 0.03, the results after 60,000 generations of training are shown below.

After adjusting hidden layers, the results after 20,000 generations are shown below.

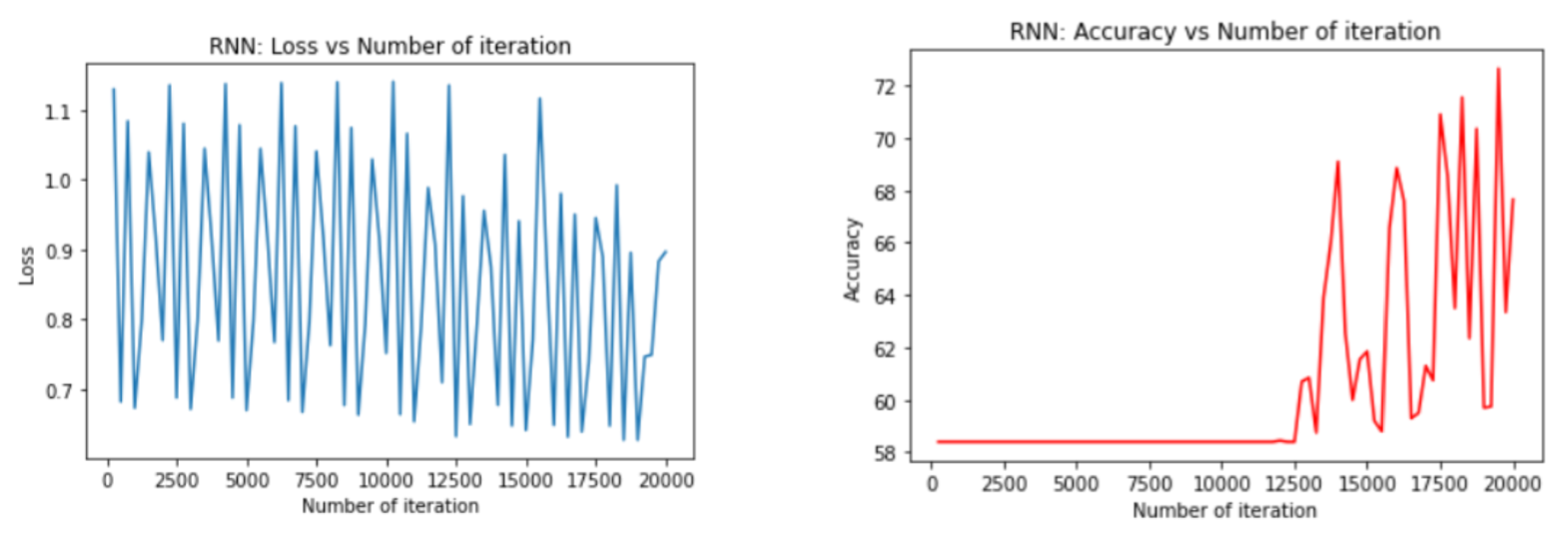
Analysis of Results
This is a triple classification problem on the emotion of NLP. The results are shown as below.
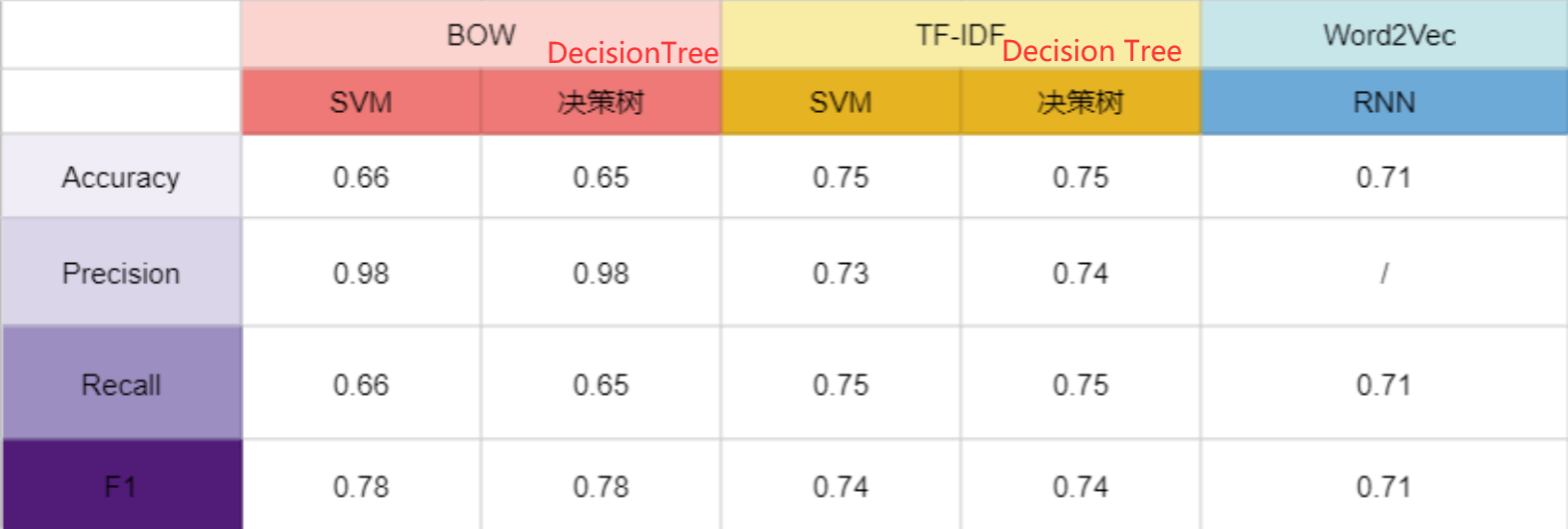
As can be seen from the above graphs, the SVM and Decision Tree algorithms have very little impact on the actual results, and the most important factor affecting the prediction results is the Embedding method. In this dataset, TF-IDF is more effective than BOW. In the end, the results of TF-IDF+SVM, TF-IDF+Decision Tree and Word2Vec+RNN are similar. The reasons for this result are as follows:
- The original dataset is not evenly distributed, and there are more “neutral” comments than “positive” and “negative” posts, so in the predictive classification process, most of the postss are not evenly distributed. The majority of posts tend to be classified as “neutral” in the prediction classification process, which is of course consistent with the actual situation. This is why the Embedding method has a greater impact on the results than the classification method.
- The dataset is not large enough. I thought that a data set of about 10,000 would take a lot of training time, but Kaggle can use GPUs and the CPU speed of Kaggle is not slow, so I could have done it directly with the original data set of 10W, and the result would be better.
- Parameter optimization. It is only fair to use the optimal parameters of each model for comparison of results.