How to get a subgraph using SPARQL query in Python
Knowledge Graph is one of the most common forms of Factual Knowledge. Many researches have combined pretrained language model with knowledge graph to improve its performance on NLU tasks. Before injecting the knowledge into the model, we should go through the tagging (named entity recognition), entity grounding (entity linking), and retrieving (e.g. SPARQL)process. This blog is talking about how to get a specific subgraph by SPARQL queries.
Introduction
As a query language, SPARQL can be used to add, remove and retrieve data from RDF-style graph databases. Wikidata use SPARQL to retrieval its subject-predicate-object triplets. Wikidata provide a gentle introduction to the Wikidata Query Service. However, it is only suitable for non-complicated situations. For instance, given a subject and a predicate, to find the object.
In knowledge-based NLU(natural language understanding) tasks, we usually need to find the subgraph of an entity. For example, given a sentence Bert likes reading in the Sesame Street Library., the NER process has found 2 entities Bert(Sesame Street) and Sesame Street, and these 2 entities are linked to wikidata ids(Q584184 and Q155629). Then we need to find subgraphs which take the 2 entities as center respectively.
To make it easier to understand, we could run SPARQL in Wikidata Query Service before we run it in Python.
Construct the query
They final query is complicated, so we start trying to decompose it.
Final query:SELECT DISTINCT ?label ?property ?propertynameLabel ?value ?valueLabel
WHERE {
wd:Q584184 ?property ?value .
wd:Q584184 rdfs:label ?label .
SERVICE wikibase:label { bd:serviceParam wikibase:language "en" }
?propertyname wikibase:directClaim ?property
FILTER (STRSTARTS(STR(?property), "http://www.wikidata.org/prop/direct"))
FILTER (STRSTARTS(STR(?value), "http://www.wikidata.org/entity"))
FILTER (langMatches(lang(?label), "EN"))
} limit 20
At first, we could make a simple query.
SELECT DISTINCT ?property ?value |
The result is shown below:
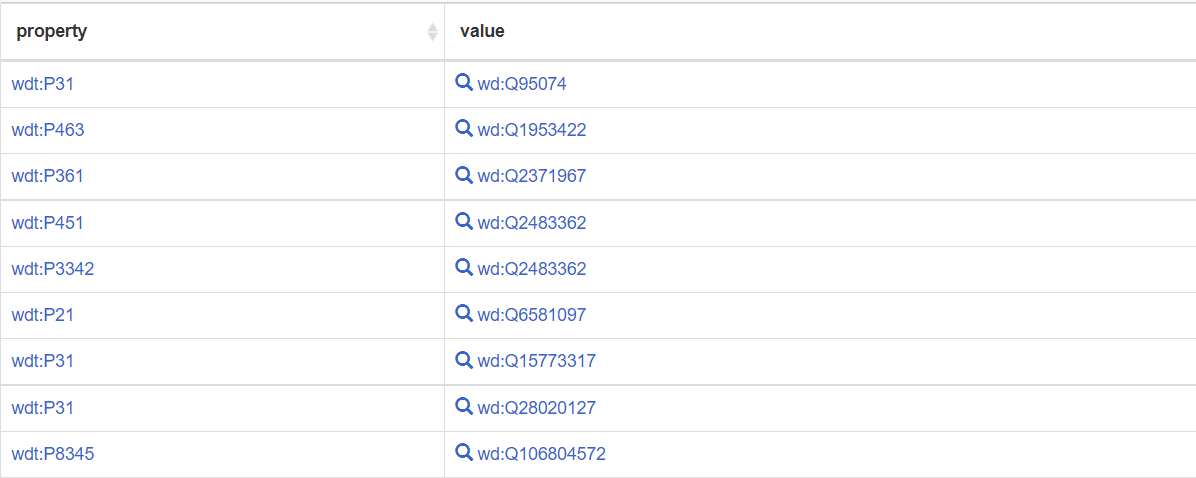
We can only find the wikidata id of object and predicate. Now we try to find what the wikidata id means.
Find the object label:SELECT DISTINCT ?property ?value ?valueLabel
WHERE {
wd:Q584184 ?property ?value .
SERVICE wikibase:label { bd:serviceParam wikibase:language "en" }
}
We could get the result:

Find the predicate label:SELECT DISTINCT ?property ?propertynameLabel ?value ?valueLabel
WHERE {
wd:Q584184 ?property ?value .
SERVICE wikibase:label { bd:serviceParam wikibase:language "en" }
?propertyname wikibase:directClaim ?property
}
Result: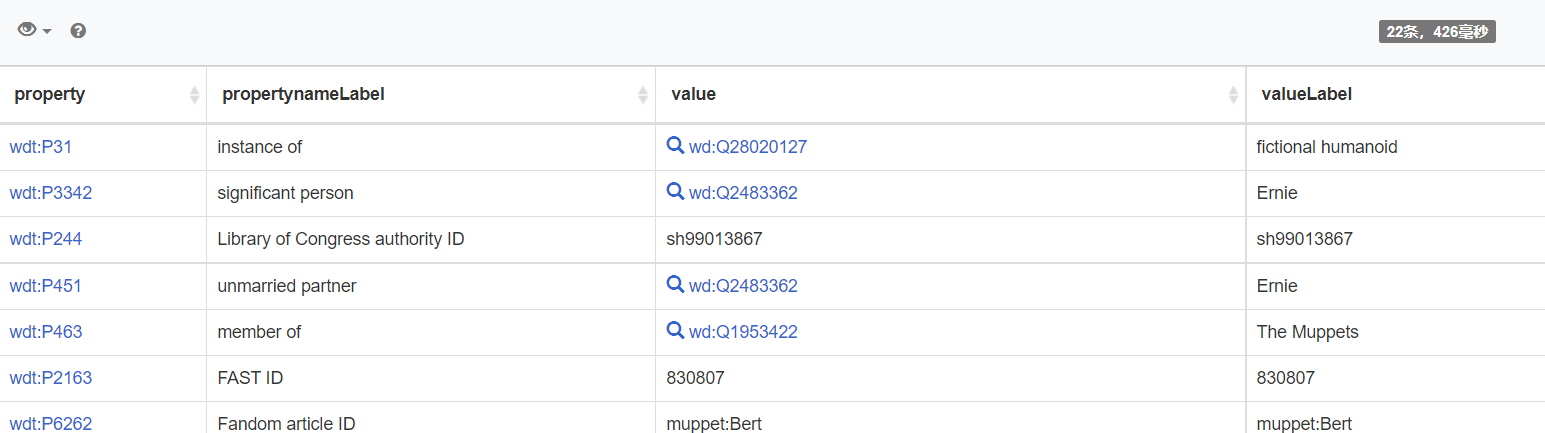
We want to get the subgraph of the specific entity Bert. But now there are many numbers and strings in the result. For example, the FAST ID of Bert is 830807. Obviously, 830807 is not an entity and we only want entities in our object results. So we need to limit the prefix of the predicate and object.
SELECT DISTINCT ?property ?propertynameLabel ?value ?valueLabel |
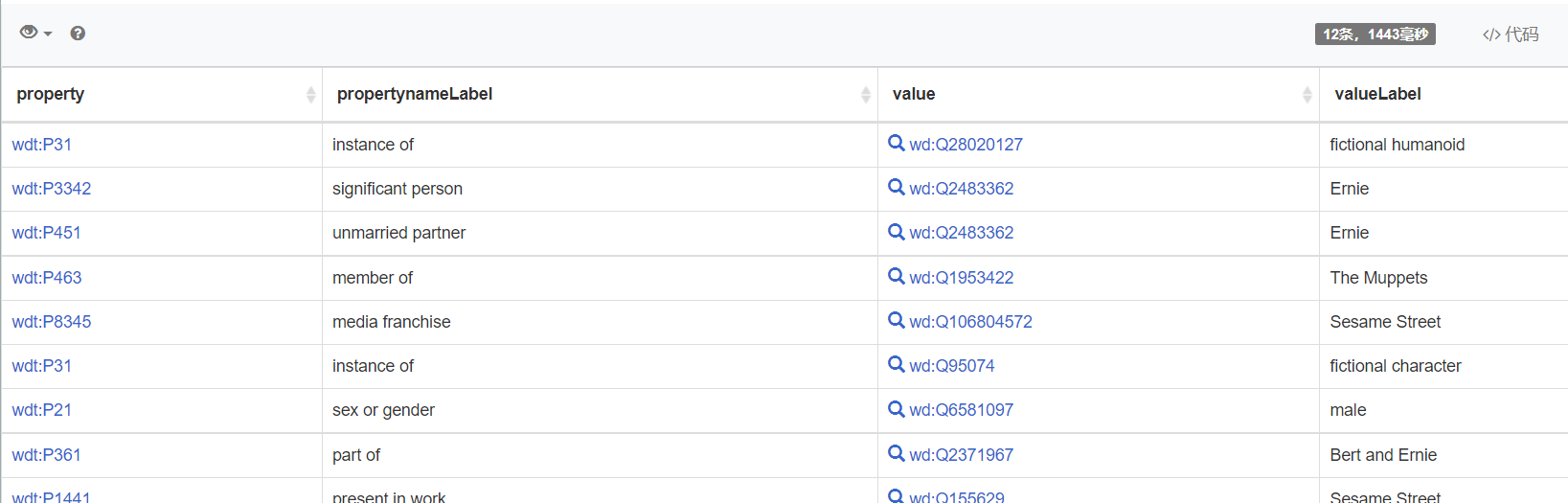
We can see that we filter the number objects out.
Finally, we get the label (english) of subject.
SELECT DISTINCT ?label ?property ?propertynameLabel ?value ?valueLabel |
Here is the result:
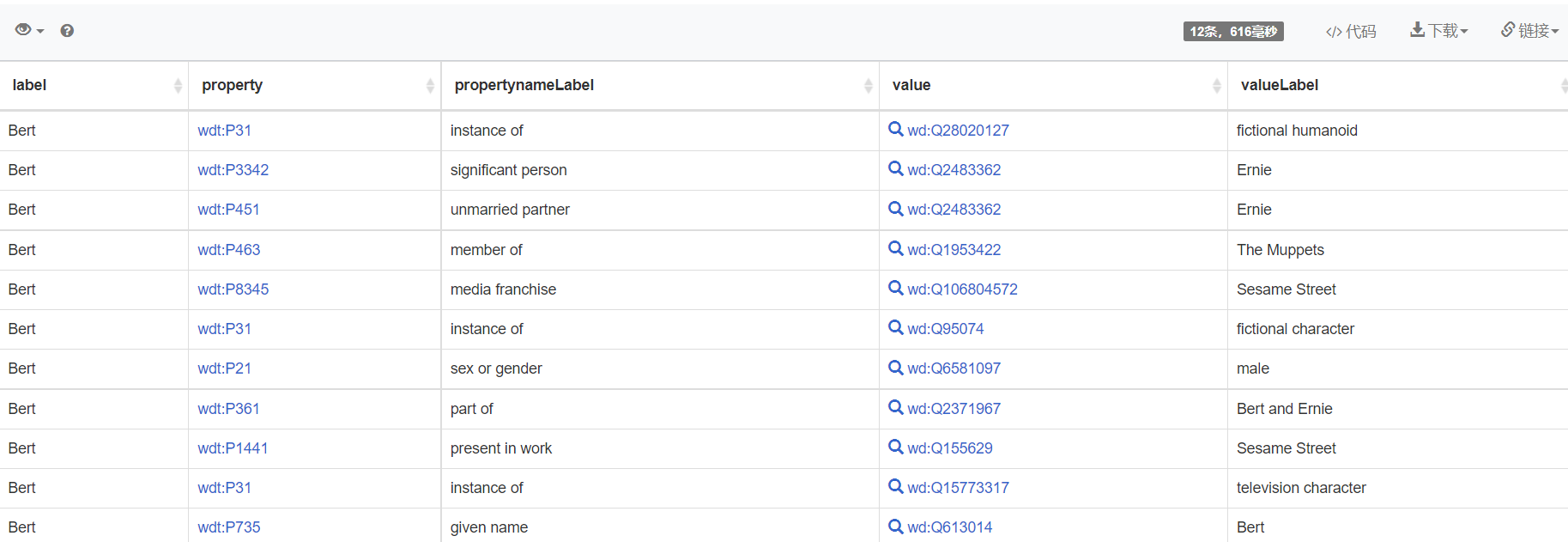
Query in Python
I use qwikidata to search wikidata online service in python. There are other Wikidata Tools like go-wikidata.
You can also use wikidata dump to search at local.(I don’t recommend it because it is really resource-consuming. A tutorial)
Here is all methods of wikidata access
Query in python:from qwikidata.sparql import (get_subclasses_of_item,
return_sparql_query_results)
sparql_query = """
SELECT DISTINCT ?label ?property1 ?property1nameLabel ?value1 ?value1Label
WHERE {
wd:%s ?property1 ?value1 .
wd:%s rdfs:label ?label .
FILTER (langMatches( lang(?label), "EN" ) )
FILTER(STRSTARTS(STR(?property1), "http://www.wikidata.org/prop/direct/"))
FILTER(STRSTARTS(STR(?value1), "http://www.wikidata.org/entity/"))
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
?property1name wikibase:directClaim ?property1.
} limit %d
""" % (wikidata_id, wikidata_id, result_num)
try:
res = return_sparql_query_results(sparql_query)
# print("finish query.")
for triple in res['results']['bindings']:
subjection_id = wikidata_id
subjection_name = triple['label']['value']
predicate_id = triple['property1']['value'].split("/prop/direct/")[1]
predicate_name = triple['property1nameLabel']['value']
objection_id = triple['value1']['value'].split("/entity/")[1]
objection_name = triple['value1Label']['value']
triple_list.append({"subjection_id": subjection_id, "subjection_name": subjection_name,
"predicate_id": predicate_id, "predicate_name": predicate_name,
"objection_id": objection_id, "objection_name": objection_name})
return triple_list
except:
print("Error in wikidata_id: {}".format(wikidata_id))